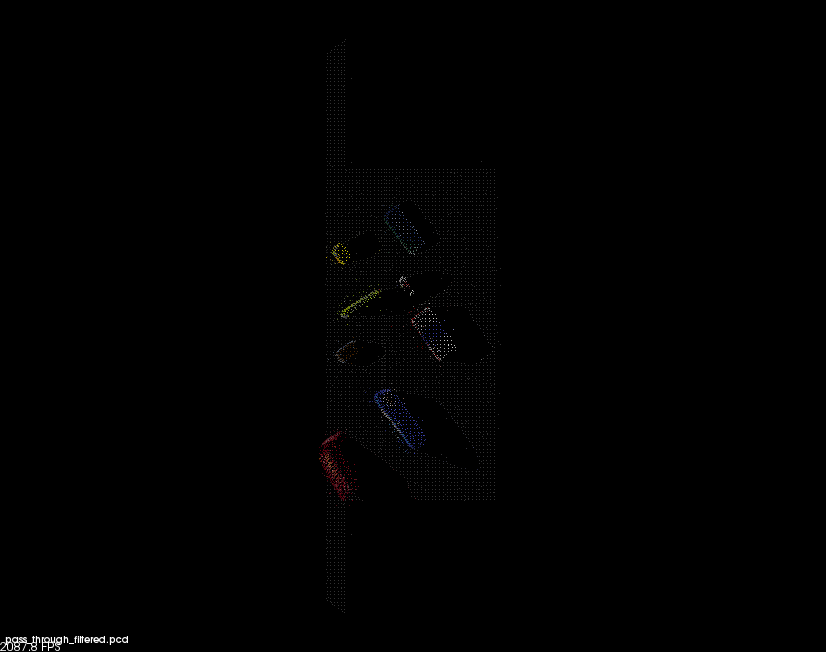For years I was a die hard user of vi. It was my goto editor of choice. Simple, yet powerful, if you knew some of the commands and understood its basics. Without fail it was available on all the unix and linux servers. In short, it did the job.
Yet as IDEs advanced, it missed some of the features that I really liked when programming, such as code completion and syntax error highlighting.
It was the reason, I started to use Atom and then, after overcoming my anti-Microsoft believes, Visual Studio code.
These features, are now available via LSP (Language Server Protocol) for Vim and NeoVIM. Ironically LSP was developed by Microsoft for Visual Studio Code and is now an open standard.
So the question, was should I try using NeoVIM or just stick with VIM? I’d looked at NeoVIM briefly a while back and didn’t really understand what the difference was. NeoVIM was a rewrite focusing specifically on APIs, extensibility and as being a drop in replacement for vi/VIM. I didn’t understand what the advantage was to me as a general user.
To that end, I thought I’d set both up, via googling and see what the difference were.
Now before you start this yourself. Be aware, that configuring and tweaking everything to your liking, can be time consuming. Then you have to remember what you did and leverage that an on going basis – so every machine will need to be setup the same.
It can make you very productive but just think of that initial learning curve.
What I learnt through the process is, besides the different configuration files, is that there is now feature parity for the most part between the two editors. A few features like neovim telescope are unique to neovim only.
I setup vim and then decided to try NeoVIM. So my setup for NeoVIM is a superset of the VIM configuration. I simply had learnt more and put it to use when I setup NeoVIM.
For now I’ve decided to go with NeoVIM and have Vim available as a fallback. Such that I aliased vim to nvim with alias vim="nvim".
My configuration is still a little fluid. If you’ve got some tips, please leave them in the comments. What have you chosen? What did you like or dislike about a plugin?
You have the most fantastic and revolutionary idea, that is going to change the world. You are stuck! It dawns on you, the data to train your model, simply doesn’t exist.
This paradox, of being without data, would sound familiar to so many. Why is this the case?
You’ve completed the training, done a tonne of experiments with known data. Everything seems fine, the ideas for how to use this newly acquired knowledge, have been brimming away in your subconscious.
Now you are ready to apply your idea to the real world.
Then reality hits! You simply don’t have the data that you need to train a model, that will enable your idea to flourish. To maybe even create your next startup.
This is the biggest challenge many AI startups have, is finding the data they need.
There are basically three ways to get data:
download or acquire it, from an external source,
generate it, from a simulator; or
use sensors in the real world to aggregate a source of your own data.
The last two are very expensive options. Simulators are essential for Deep Reinforcement Learning. Collecting data from sensors, still for the most part, requires augmentation to make it useful, in most Deep Learning scenarios. Not to mention of course, the need for labelling.
So the first is the cheapest, that is to find an existing source of labelled data. There is plenty of known data sets out there.
It all seemed to work so well in the training programs. But why is there not more data? Why is the set of available data sets so limited?
I’ve been asking myself those very questions of late. The best answer I’ve found, is that the Academic researchers are just using the existing sources of labelled data and making incremental improvements on deep learning algorithms. That is, if they invested in creating new sources of data, for new deep learning techniques, they probably wouldn’t get their research done. It is why everything that you’ve learnt just works effortlessly. They’ve been at it for a while now….
So the next question becomes how do I get the data?
You have to create your own data sets! Don’t under estimate the effort needed. Without data you just have an idea!
Homebrew is your best friend to help you setup your new MacBookPro for development. Install homebrew first by following the installation instructions on the homepage.
Its often easier to use brew install <something> then to maintain everything separately.
Yes I still like to use a terminal and the command line at times.
Things I’ve setup are:
iTerm2 – is a replacement for the standard Terminal program
Oh My ZSH – its used to manage zsh configurations and comes with a tonne of helpers
powerlevel10k – is a Zsh theme, that is fast and configurable
neofetch – it displays information about your system
miniforge – is a minimal conda installer specific to condo-forge that works with Apple Silicon
rust-lang – is a programming language with a set of development tools. Toolchain management occurs with rustup. Whilst that can be installed via homebrew, I choose the native install from the installation instructions
Visual Studio Code – is a code editor. There now is a Mac Universal build as well as if you go hunting an Apple Silicon only one under alt-downloads
XQuartz – if you intend to log into linux servers and display X screens this is a must. It has native Apple Silicon support now
Oh My Zsh
OhMyZsh has a lot of plugins. The ones I’ve selected are plugins=(zsh-autosuggestions zsh-syntax-highlighting git extract z rustup cargo rust macos history)
Make sure you select to install the recommended nerd font MesloLGS-NF. Its give you all the icons on the command line. If you install Powerlevel 10K under iTerm2 it’ll update the font settings by default. You may need to manually adjust under Terminal.
Miniforge
I was originally going to just use the default anaconda installer. However that uses Rosetta. Miniforge has native support for Apple Silicon. I installed it using brew install miniforge but there is an Apple Silicon native installer under the download sections.
Still need to determine if the python installation is running under rosetta or is a native Apple Silicon app. However by using homebrew, it its not at some point soon it will be updated.
The main thing I want working is jupyterlab notebooks. This can be done with conda install jupyerlab.
Don’t forget to run conda init zsh for it to automatically update your .zshrc file. Afterwards you’ll also notice that powerlevel10k will display your current conda environment.
ssh
I hate typing in passwords and in general setup ssh and copy ids about.
First you need to generate a ssh key ssh-keygen -t ecdsa -b 521 and then use ssh-copy-id <user>@<hostname>. Afterwards you should be able to log into your linux servers. This worked for me on Ubuntu 20.04.
Other tools
Of course I setup Xcode. Homebrew will automatically install the Xcode command line tools.
Playing around and trying out different things, I managed in an afternoon to set my new MacBookPro up to how I basically like it. Some more tweaking over time and I’ve yet to tweak vim.
Really looking forward to seeing how I can leverage the M1 Max chip in my projects to do with OpenCV and deep learning. That’ll be another post in the future.
It finally arrived this week. I’m the proud new owner of a MacBookPro 16″ with the M1 Max, 32GB of ram, a 24 core GPU and 1 TB hard drive.
It took a month for it to be delivered. It was shipped all the way from Shanghai, to my door. I bought it online via the Apple Store and you get notifications every step of the way.
For a couple of years I’d been reading all the reviews and thinking to myself when is Apple going to get off the Intel bandwagon and fix their keyboards.
My linux servers were all running AMD chips, Intel just didn’t seem to be in the game, like it used to be. The Intel chips in laptops run hot, use a lot of power and the inbuilt GPUs were having trouble with the higher definition displays. I’d look at the Apple MBPs and think I can get something similar from Dell etc and just put linux on it. But I’d done that in the past …
Geez I’ve missed the elegance of using Apple devices for my main work machine. Things just work like they are supposed to and no more waiting for them power on!
For years my main development machine was a trash can Mac Pro late 2013 model, with a gorgeous 32″ 4K monitor. I had an iPad and a Mac Book Air that I used if I went travelling.
My last laptop was an Asus ROG Zephyrus G14 with 32 GB of ram and a Nvidia RTX 2060 Max-Q. I’ll still use it for simulation development under Unreal Engine. It’s a really powerful machine and I’d left Windows on it for Unreal Engine development. It came with Windows 10 and I upgraded to Windows 11.
But the fan noise is always present and sometimes it just screams at you.
The other annoying thing with the G14 was that the screen wasnt viewable when sitting outside on a sunny day at a cafe. It was fine indoors, but the display nits are lower than the Apple devices.
I live in a warmer sub-tropical environment and if you were cranking the machine up with using the graphics intensely, then the fans are really loud – you needed to wear noise cancelling head phones. Not to mention it go hot to the touch!
I had thought I’d give Microsoft another go after having ditched all Microsoft software over a decade ago. The turning point had been, that I could use Ubuntu, under Windows Subsystem for Linux and that they appeared to be supportive of open source software.
Until Windows 11, I had to revert occasionally back to my Dell XPS 13 that I had before that. This was when I needed an X display into my Linux development servers. Microsoft Visual Studio code (which also leverages the GPU) would die on the Dell XPS 13, with an external monitor attached. The XPS 13 did not have a discrete graphics card but had a great display.
My last MacBookPro was nearly a decade ago. It was just before the retina displays came out and it still had a CD/DVD player (had been converted that bay to a second drive).
I’d decided that I was better off with a more powerful desktop machine back then. Hence the trash can Mac Pro late 2013 model. It served me well and still is quite snappy for every day tasks but compiling is slow now.
Am hoping the new MacBookPro will last me five or so years. I didn’t quite go the full spec, as I new for most activities I do, that this device would be overkill. Yet there is something about getting a better specced machine. I always want a little better then I actually need. I think Apple know this and its not long before the price is really high.
But I was drawn to the M1 Max for its insanely fast memory transfer speeds which is double that of the M1 Pro.
What I’m yet to really explore is Artificial Intelligence on the M1 chip compared to using Nvidia’s CUDA.
So far I’m really liking this MacBookPro, I’ll write a few more posts about how I’ve set it up shortly. I won’t do benchmarking as there are so many YouTube videos and articles about already.
My advice to anyone buying one, is just because you have the money, don’t necessarily go with the highest specced machine that’s within your budget. There is always something new coming out next. These machines are insanely fast and you may just not need that extra ram, GPU cores or storage!
Think carefully about your workload on it before buying and select a model that suits.
Waymo has now driven 10 billion autonomous miles in simulation according to TechCrunch. Why you may ask yourself is there a need to do so, in simulation?
The majority of driving is simple and incident free. You, as a human driver, are basically on autopilot and by sticking to the rules and driving between the lines, in your lane, you nearly always arrive safe, at your intended destination. There are rarely any exceptions in your driving and edge cases, like ethical the baby & grandma scenario that people talk about are rare exceptions too.
A self driving vehicle will use an AI model, classical robotics and computer visions approaches to drive. What we are talking here is about training, the AI model components.
What an AI needs to learn from, is not only the normal driving cases, that it might encounter but also the edge cases. An edge case where a human, animal or expensive infrastructure is put at risk, is not feasible, in the real world, for acquiring data for the purposes of training an AI.
The AI needs to learn from data, and keep repeating experiments until it gets the scenario correct. This is best achieved in simulation to enable data to be acquired safely.
To that end, sdcar.ai has been working away in stealh mode in related technology, to assist with acquiring data, to create realistic simulations… we are still early in that journey.
Recently R&D work has been done on using Unreal Engine as a simulator. Unreal Engine is a popular set of tools, Software Development Kit (SDK) and runtime for creating near photo realistic 3D worlds for games. It is a powerful creation engine. The initial hypothesis, was that through using Unreal Engine, a vehicle simulator could be created, data acquired, an AI model trained, and that AI model used to control a vehicle in the simulator.
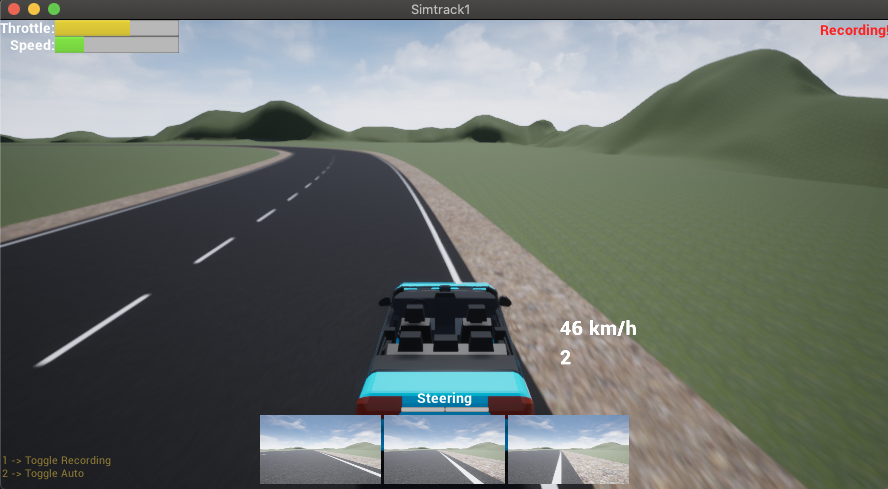
That hypothesis was indeed correct, and a GitHub repo simtrack1-ai-drive was released with details on how to use the simtrack1 simulator.
Simtrack1
This simtrack1 simulator is in its early stages, and is not fully decorated. It has sufficient detail to enable the capturing of vehicle telemetry data & camera images to train an AI model that can in turn be used to drive the vehicle.
If you are so inclined, there are instructions in the repos README.md to try running it experimentally, if you have a recent graphics card.
Some ideas for future work, include:
– creating a leaders board to capture best times around the track;
– setting up waypoints, to ensure the track is actually traversed;
– installing traffic signals;
– populating road signs with speed limits;
– speeding up the game speed, with multiple instance, to enable deep reinforcement learning;
– creating zombie people and animals that freely roam to facilitate obstacle avoidance; and
– having multiple vehicles on the road at any one time to simulate traffic.
Would love feedback but please do remember that this is an early public release.
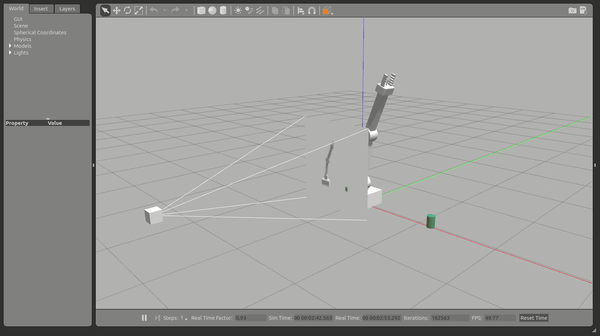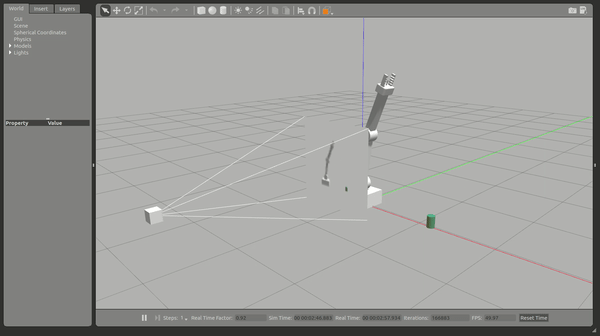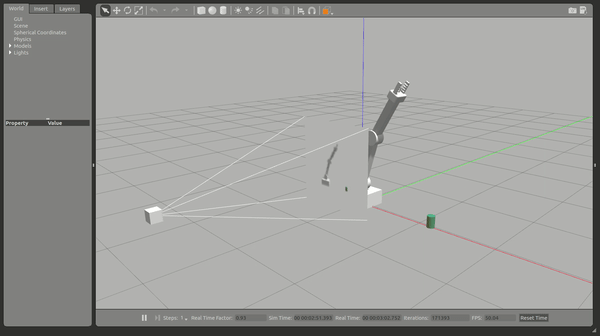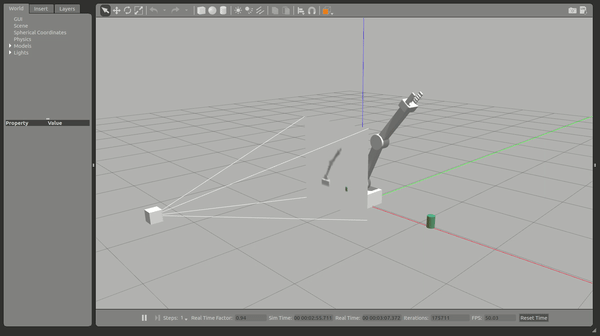
This Deep Reinforcement Learning Arm Manipulation project has two objectives to achieve using a template project. Whereby to achieve each objective we create a DQN agent and define reward functions to teach a robotic arm.
The template project is based on the Nvidia open source project “jetson-reinforcement” developed by Dustin Franklin.
Robot Arm in Gazebo simulator
The two primary project objectives are:
Have any part of the robot arm touch the object of interest, with at least a 90% accuracy for a minimum of 100 runs.
Have only the gripper base of the robot arm touch the object, with at least a 80% accuracy for a minimum of 100 runs.
Written by Nick Hortovanyi
Reward functions
The reward functions are defined in ArmPlugin.cpp. The arm joints were updated using position control (as that was the programs default setting). For each joint there are two actions (either increase or decrease joint position).
REWARD_WIN was set to 0.125 (0.1 2nd objective) with REWARD_LOSS to -0.125 (-0.1 2nd objective).
If the robot gripper hit the ground a REWARD_LOSS * 10 was given and the episode ended.
Interim rewards, within the episode, were issued if there was no ground contact or 100 frames had beed exceeded.
The main interim reward was based on the distance goal delta between the gripper and the cycling prop. If a positive weighted average was derived then a REWARD_WIN was recorded otherwise REWARD_LOSS * distance to goal was issued. Thus the REWARD_LOSS was higher the further away from the goal the arm was.
For the gripper base (2nd) objective an additional REWARD_LOSS was added if the absolute average goal delta was < 0.001 to penalise no movement.
If the robot arm hit the prop, a REWARD_WIN * 10 was used for the first objective otherwise a REWARD_LOSS * 5 for the second objective if the collision was not with the gripper_middle.
However for the second objective a REWARD_WIN * 20 was issued if the collision point was gripper_middle.
Any collision ends the episode.
Hyper Parameters
Image dimensions were set to the same size as the input. Training was performed on a GTX1070 and there was no need to restrict memory usage. INPUT_WIDTH 64 INPUT_HEIGHT 64
OPTIMIZER "Adam" was chosen as it in general performs better then RMSProp whilst maintaining its advantages.
For objective 1 the LEARNING_RATE was 0.1 with REPLAY_MEMORY at 1000. The value was chosen via trial and error.
For objective 2 the LEARNING_RATE was decreased to 0.01 due to the higher REPLAY_MEMORY set at 20000. The higher REPLAY_MEMORY was used so as to allow for more discrete learning, due to the smaller surface area required to achieve a collision to meet objectives.
For both BATCH_SIZE was set to 512 (again sufficient memory on the GTX 1070).
LSTM was used USE_LSTMtrue with LSTM_SIZE256 which was set via trial and error.
Results
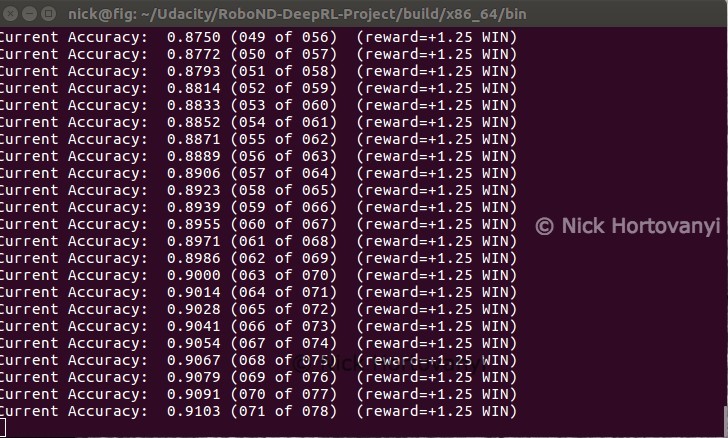
Objective 1 – Have any part of the robot arm touch the object of interest, with at least a 90% accuracy for a minimum of 100 runs.
Results objective 1
The robotic arm quickly learnt how to hit the prop with a degree accuracy in a repeatable fashion. On occasion if the arm trained initially away from the prop, it would take longer to achieve a higher accuracy.
Once a winning path was learnt this configuration consistently had the robotic arm quickly hitting the prop objective.
As can be seen in the above summary output the objective was achieved well within the criteria specified.
Objective 2 – Have only the gripper base of the robot arm touch the object, with at least a 80% accuracy for a minimum of 100 runs.
Results objective 2
With the finer control required, and alteration to the interim reward system, this configuration would often hesitate before making a move. Whilst it learnt quickly how to get very close to having the gripper_middle hit the prop, it would also often just miss either hitting the ground or the arm itself hitting the prop. There seemed to be a repeatable pattern, of just extending past and swinging down in an arch, that once learnt gave consistent winning results.
Occasionally the middle joint would collide with the ground and this would lead to the objective not being met.
This configuration was not always reproducible, however with the above screen shot it was able to meet the objectives.
Future work
There were clear arcs that once found achieved a win quickly. Such that it would be worthwhile investigating an interim reward system based on not just the distance from the goal but also distance from an ideal arc trajectory as the arm approached.
Further using centre points to calculate distance from goals becomes less accurate the closer to the goal the arm is. Such that other points like the end of the gripper_middle and top of prop cylinder, would be worthwhile experimenting with.
The third project in term 2 of the Udacity Robotics Nano Degree program requires students to use ROS and Gazebo along with RTAB-Map, to create a 2D occupancy grid and a 3D octomap of two environments – one supplied and the other student created.
Students extend a previous robot creation to upgrade sensors to supply the necessary sensor messages for RTAB-Map. This leverages the laser scanner, IMU/Wheel Encoder but replaces the camera with a RGB-D camera (ie kinect).
Further the ROS project is created with all links connected with appropriate naming and mapping.
The robot is launched and teleoped around the room to generate a map of the environment.
After successfully mapping the supplied environment, a student defined environment is created and mapped using the same technique.
Introduction
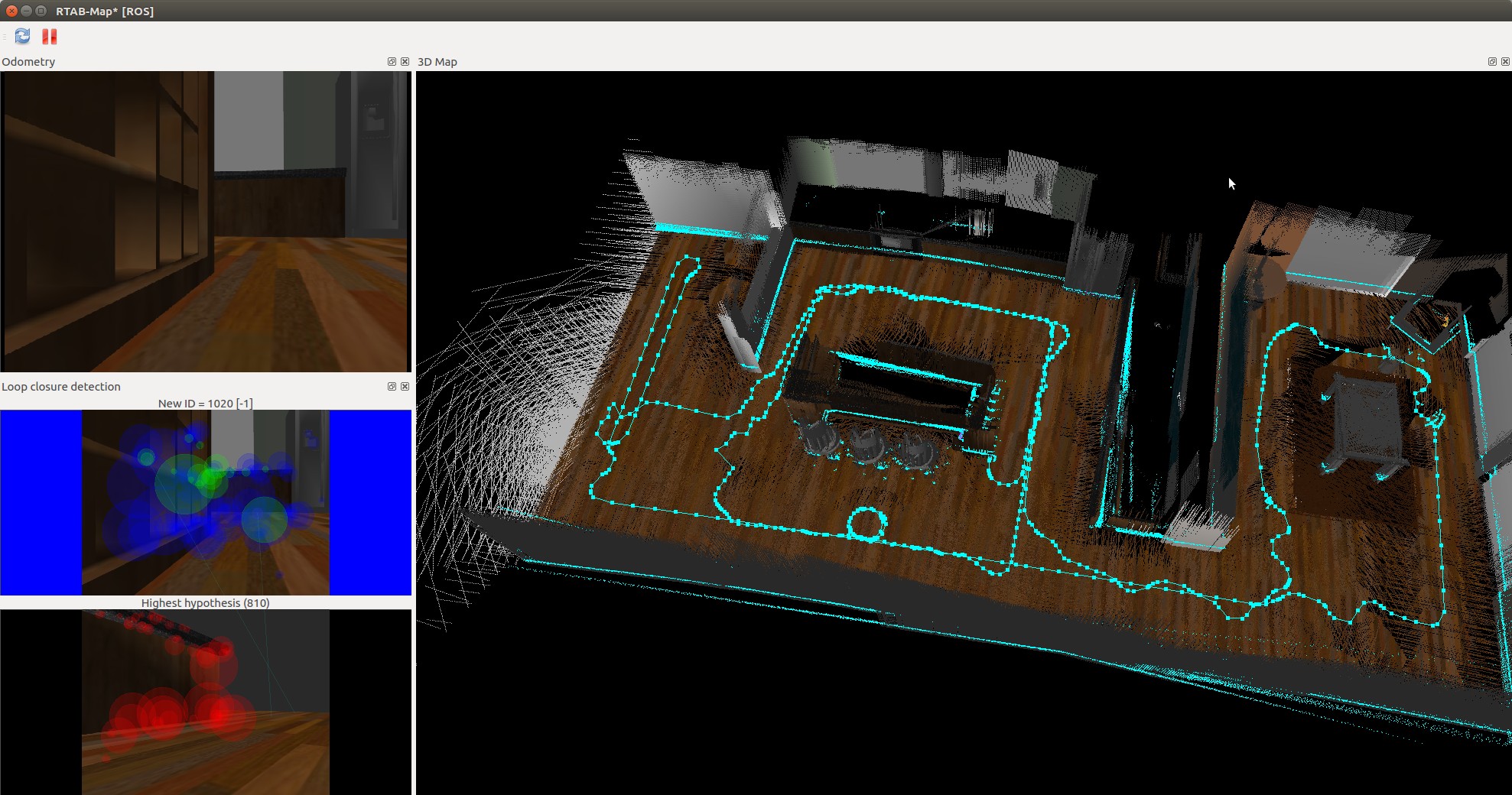
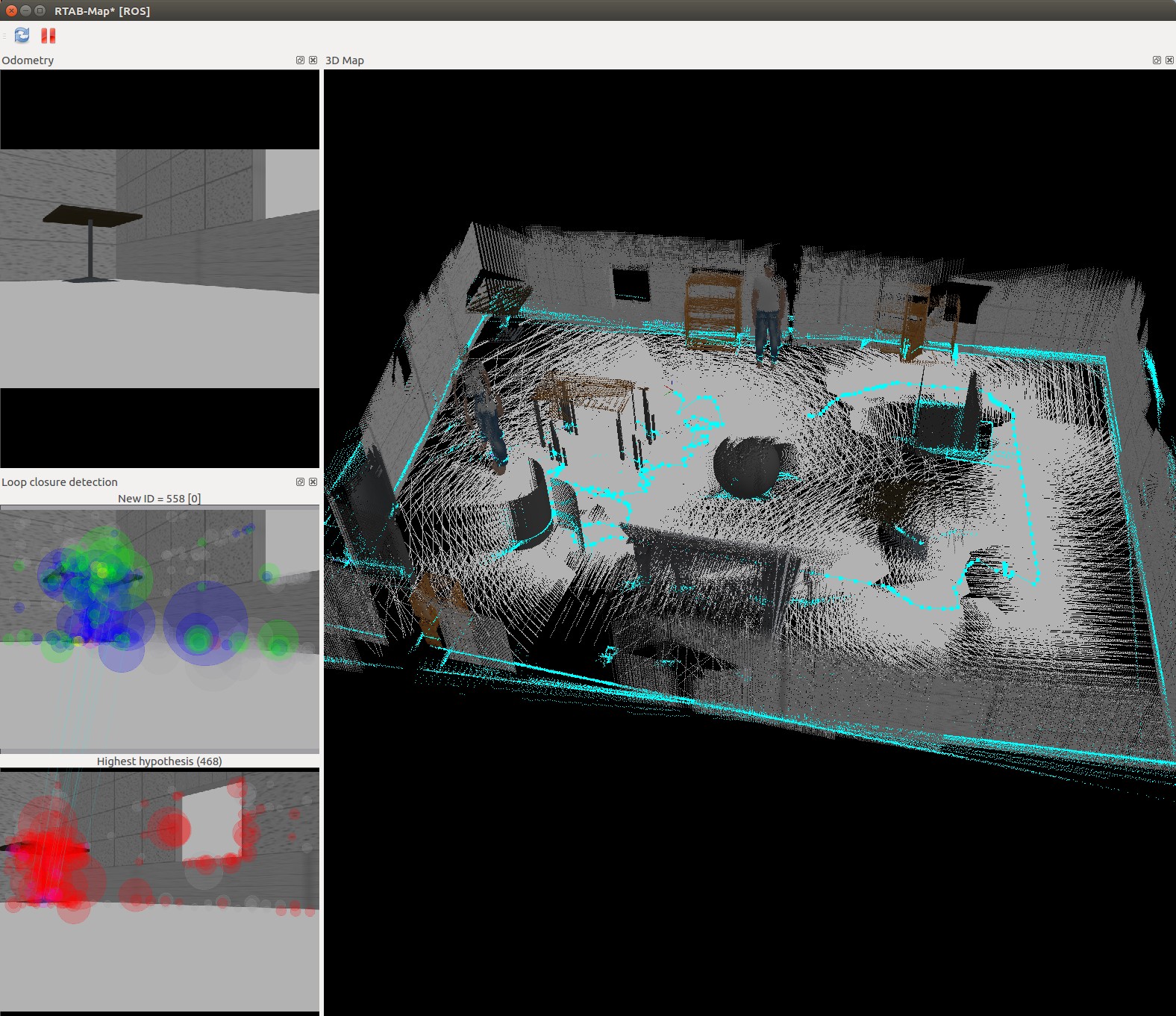
In this project a robot model uses a Simultaneous Localisation and Mapping (SLAM) technique called RTAB-Map (Real-Time Appearance-Based Mapping). It is a RGB-D Graph Based SLAM approach that uses incremental appearance based loop closure detection.
The RTAB-Map ROS wrapper is leveraged with visual representation in real time via rtabmapviz. The resultant map is stored in local database that be later interrogated via rtabmap-databaseViewer.
Background
When a robot encounters a new environment where there is no supplied map, it needs to be able to create this map and localise its pose using it. This combined localisation and mapping process is referred to as SLAM (Simultaneous Localisation and Mapping).
The Occupancy Grid Mapping is a 2D algorithm where each grid cell is identified as Unknown/Undiscovered Zone, Free Zone or Occupied. This represents a slice of the 3D world.
The Grid-Based FastSLAM approach combines SLAM (Synchronised Location and Mapping) using a MCL (Monte Carlo Localisation) Algorithm and an Occupancy Grid Mapping. The main advantage of is the MCL particle filter approach but it always assumes there are known landmark positions. Thus it is unable to model an arbitrary environment.
Graph-SLAM uses a graph based approach to represent poses, features from the environment, motion constraints (between two poses) and measurement constraints (ties together a feature and a pose). It solves the full SLAM problem, it covers the entire path and map and not the most recent pose.
This project uses RTAB-Map, which is a Graph-SLAM approach that uses loop closure with Visual Bag-of-Words for optimisation.
The loop closure detection occurs against working memory to constrain the number of images interrogated. Working memory can be transferred and retrieved from long term memory to reduce complexity. The algorithm used for loop closure detection is SURF (Speeded Up Robust Features).
The possible outputs of RTAB-Map are 2D occupancy grid map, 3D octomap or a 3D point cloud.
Robots are of varying dimensions inclusive of height. Whilst mapping a 2d environment may show where fixed walls etc are it does not take into account height. A robot, that is propelled on the floor, may be able to navigate under some obstacles but not others eg a chair vs a large table. Hence the need to understand the environment from a 3D perspective.
However building a 3D map is more costly then a 2D map. This is not only in terms of Compute & Data costs but also in the cost of the sensors required. However, simple sensors such as a single camera may be cheaper but the algorithms required can be more complex.
Robot Model Configuration
The robot model used was based on the nick_bot created in the previous project as the student robot model (which had a square base with two actuators for the left and right wheels). The camera was removed and replaced with a kinect leveraging the openni_camera ros package with the gazebo controller Openni Kinect.
No changes were made to the hokuyo laser range finder.
An additional joint was added to rotate the kinect data 180%. It was positioned on the front of the robot so as to not interfere with the laser range finder.
The nick_bot configuration files can be found under the urdf directory.
Two worlds were created in gazebo – one supplied as kitchen_dining.world and the other student customised nicks_building.world
kitchen_dining.worldnicks_building.world
Fixtures were selected in nicks_building.world to give sufficient points for the SLUR algorithm to detect distinct points. Items were also placed to ensure that the features could not be mistakenly detected twice ie a person was placed next to one of the bookshelves. Sufficient space was left for the robot to navigate.
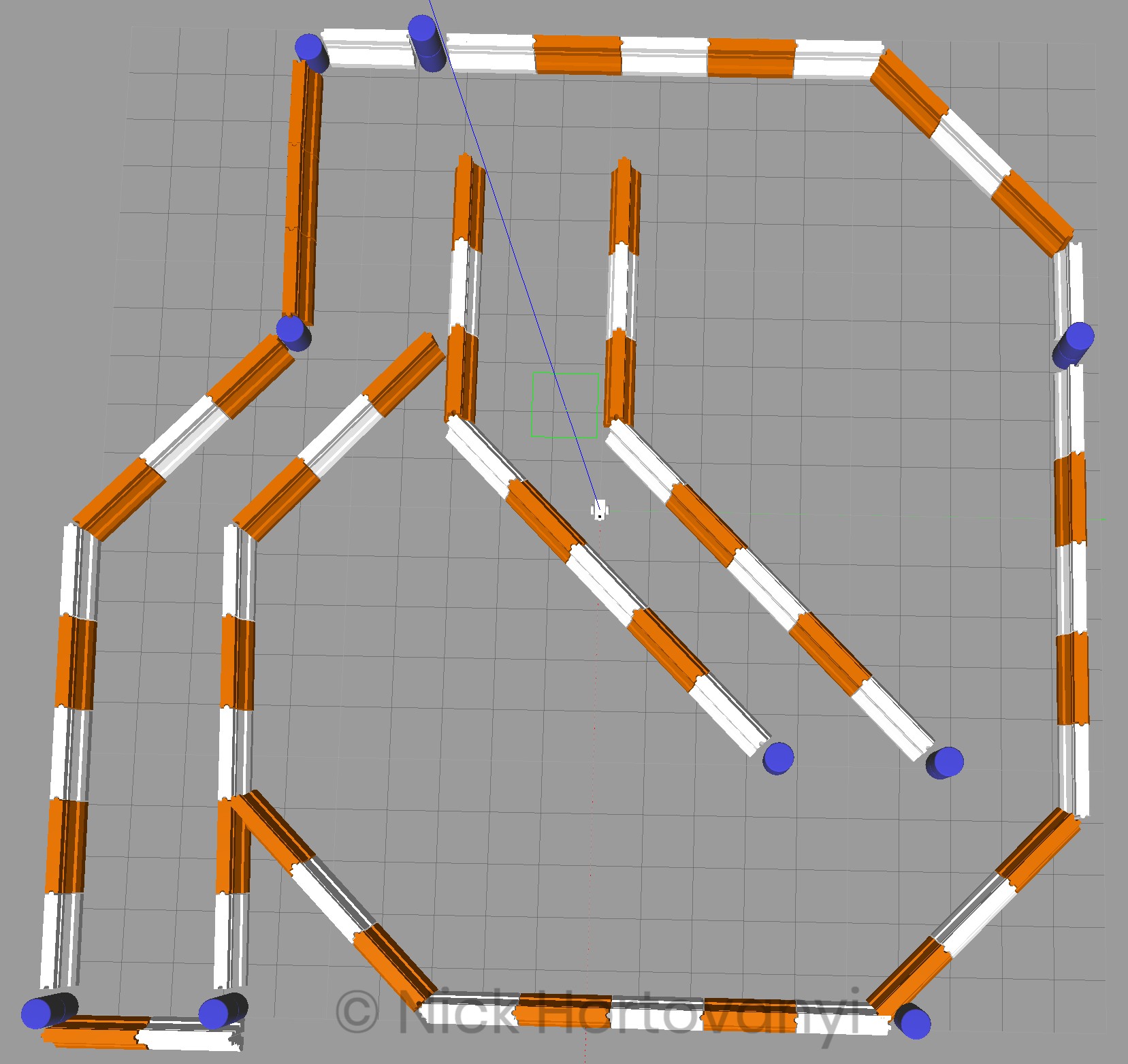
The following tree diagram depicts the package structure and files that made it up.
This tree structure was chosen based on the previous student project that conformed to known gazebo/ros standards with the addition of an output directory to store Udacity project writeup requirements.
Results
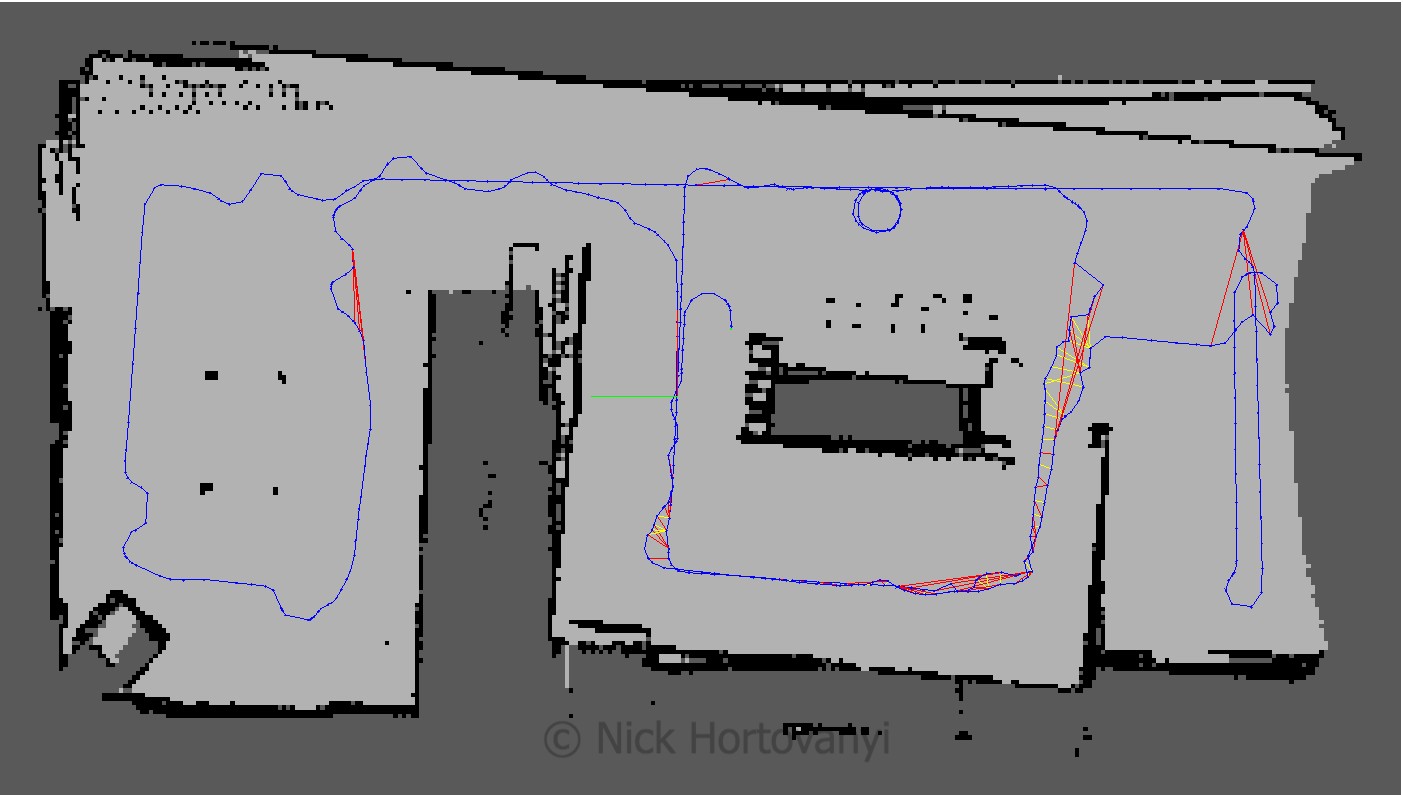
kitchen_dining_3d
kitchen_dining_2d
nicks_building_3d
nicks_building_2d
Discusion
The robot was teleoped (navigated via the keyboard) around the room. At some points the robot did not move forward. This appeared to be when it started to perform loop closure. Kp/MaxFeatures was halved to 200 and Vis/MinInliers was reduced from 15 to 10.
However the 3D map quickly started to resemble the physical kitchen dining gazebo model. To improve loop detection rates some, on the spot circles were performed. Of particular note were the features in the main kitchen area. More SURF features were identified there as there was more variation in the surface s.
The nick building gazebo model wall surfaces were tiled, repeatable pattern with lack of other discerning features sometimes caused the loop closure detection to map to an incorrect previous image. This then distorted the map. Additional features were added to achieve a successful map.
The kitchen_dining model performed significantly better then the student created nicks_building model. This was due to the richer and more complex features of the kitchen_dining model.
Future Work
Mapping is important to help understand the world. There are a plethora of sensors and of interest is the about to arrive solid state lidars. As the price point of these sensors continues to drop it will open up opportunities to create richer and more realistic 3D maps at a cheaper price point.
Being able to map an environment cost effectively to create a replicated virtual world will increasingly be important to allow for the training of deep learning models. We are actively looking to do this and then supplant the trained model back into a robot so it can navigate in the original environment that was mapped.
The second project in term 2 of the Udacity Robotics Nano Degree program requires students to complete a hijacked robot scenario using ROS and Gazebo.
Students are to initially follow instructions for a building a reference robot model, before tuning the localisation parameters satisfactorily such that the robot within the Gazebo maze simulation can reach an end goal.
After completion of that, a new robot model is created with alterations to the base and position of sensors. Whereby it uses the same simulation and must reach the same end goal.
Introduction
In this project a robot model has to use localisation to work out where it is. It creates a rolling local map using laser range sensors. The local map in turn is used to navigate towards a navigation goal.
The navigation stack utilised move_base. It provides a local cost map, as the robot moves, in relation to a global cost map to define a continuous path for the robot to move along.
This project utilises Gazebo to create a simulation with a map provided by Clearpath Robotics
Once the robot has reached the navigation goal, the objective of the project has been achieved.
Background
A robot needs to understand where it is in a world, to be able to make navigation plans to get from point a, to point b, whilst avoiding obstacles. The process of understanding “where am I?” (from a robots perspective) is called localisation.
This project uses a localisation package built into ROS called Adaptive Monte Carlo Localisation (AMCL) to assist with the robot in a scenario to work out where it is. Hence the project name “Where am I?”.
AMCL is a variant of the Monte Carlo Localisation (MCL) which was learnt in the course material. MCL uses particles to localise the robot pose. It has several advantages over using Extended Kalman Filters (EKF) such as uses raw measurements (ie from lasers), is not reliant on gaussian noise, is memory and time efficient, and can perform global localisation.
The AMCL package adaptively alters the number of particles used, which has the advantage of reducing the computational overhead required.
Results
We first completed this exercise using the class room example which is named udacity_bot. Then a different version was created where the base and sensor locations were changed. This was named nick_bot and was launched using udacity_world_nick.launch.
The final results of when it reached the goal state follow.
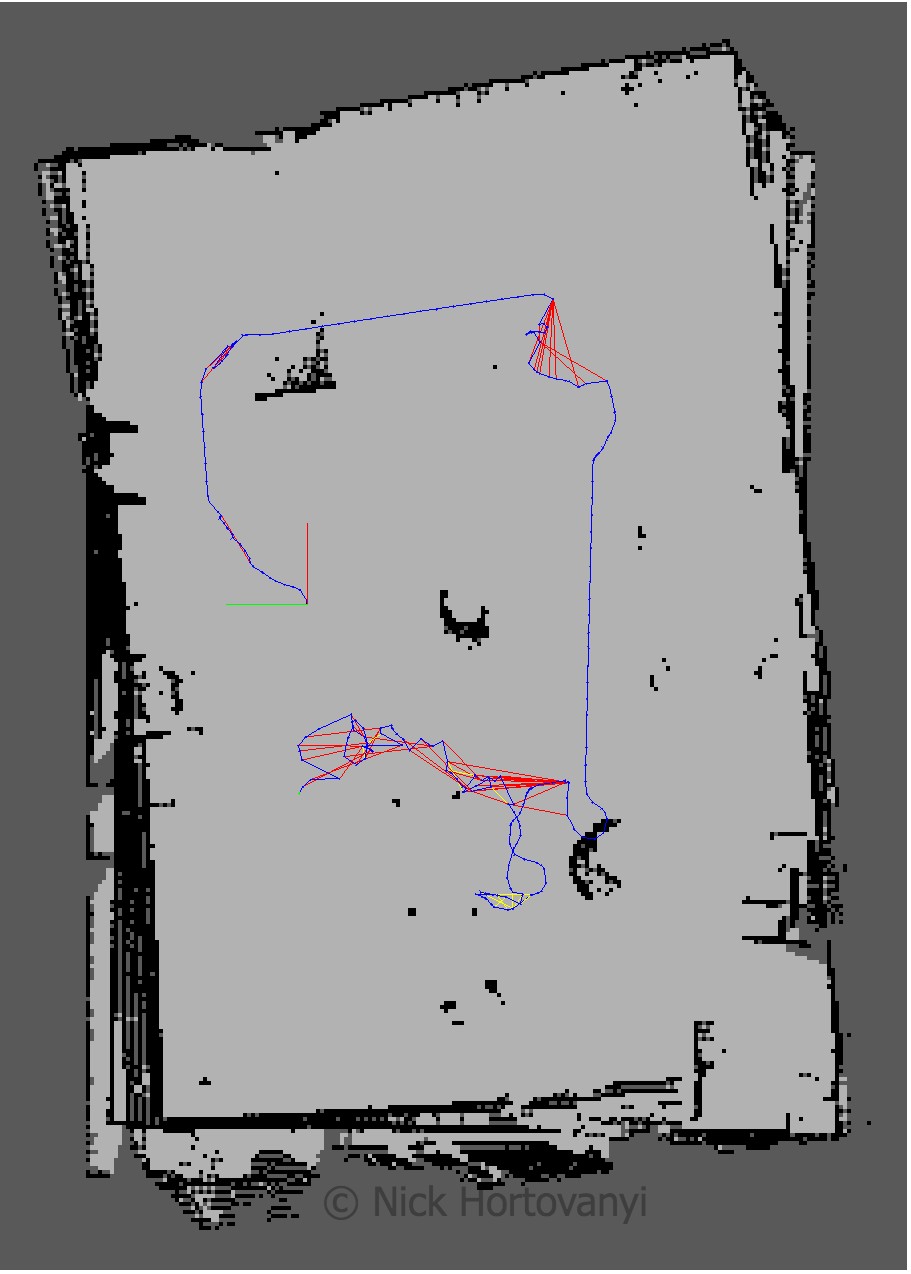
udacity_bot
udacity_bot rviz
nick_bot
nick_bot rviz
Model Configuration
This discussion is for the configuration of nick_bot.
The nick_bot was a square version of the rectangle based udacity_bot. The laser sensor was moved to the front of the robot.
The amcl_nick.lauch. Wherever possible the same configuration and parameters as the udacity_bot used amcl.launch.
min_particles was set to 25 and max_particles to 200 to not heavily utilise CPU. A higher max_particles did not improve initial ability of the robot to find itself with certainty.
odom_alpha1 to odom_alpha4 were trial & error values and changed from the default of 0.2 (there was not much documentation about).
The laser model parameters were left as default. There appeared no reason to change them as they were clearly visible on the above rviz visualisations and aligned to the barriers.
The yaw_goal_tolerance and xy_goal_tolerance were doubled from the default values to allow for additional flexibility in trajectory planning.
transform_tolerance was set 1.25 and update_frequency to 3.0 for both local and global.
obstacle_range was set to 1.5, raytrace_range to 4.0 and inflation_radius to 0.65 to enable sufficient space on the cost map for the robot to navigate.
robot_radius was set to 0.4 in this model to allow for the larger square design.
The local publish_frequency was set to 3.0 with the global to 5.0 This configuration in conjunction with 15.0 x 15.0 sized local cost map was able to function within the performance constraints of the system used. Increasing the size of the local cost map utilise significant more computer power and missed the time windows for publish_frequency.
sim_time was set to 4 as there appeared sufficient compute resource to estimate a trajectory out 4 seconds.
meter_scoring was enabled to ensure pdist_scale used meters.
pdist_scale was set to 0.5 being less than the default of 0.6. Default and higher values appeared to cause the robot to sometimes get stuck.
Discussion
The robot model was able to on most runs navigate successfully to the goal. The route taken at times could have been shortened. However further research is required into the ROS packages used to be able to tune it to achieve such. Often the observed path taken did not appear to be the most cost affective and when it missed the target goal, it would do a large sweep before re-approaching the target.
The AMCL routine appeared to quickly gain certainty about the locality of the robot. It was the rest of the navigation stack and move_base that needed further tuning.
In the kidnapped robot problem where by a robot is positioned in an arbitrary location, AMCL would be able to adapt the number of particles used to gain certainty of the robot’s location. In addition AMCL does not rely on landmarks, but on laser based maps, laser scans and transform messages to output pose estimates.
Moreover in an environment, where by there weren’t known landmarks, the AMCL has advantages over the Extended or Unscented Kalman Filter based approaches. These environments would include those with no known map (ie its the first time being navigated) or in highly unstructured environments with lots of moving structures over time eg shopping centres with popup shops in the aisles with significant foot traffic.
Future Work
The size of the local cost map had a significant impact on performance. Higher values decreased the ability to publish within the frequency required. In addition higher particle numbers whilst increasing CPU load did not reduce the time taken for the AMCL to be certain about the robots locality.
A square designed robot model as opposed to a rectangular design appeared to enable the robot to rotate more affectively around its base. Other wheel components are available but they did not publish ODOM information. Hence additional sensors might be required with further investigation into the impact of the removal of ODOM readings required.
A laser GPU gazebo component was available. This may enable reduced CPU load by moving the workload to the GPU.
A LIDAR unit would give a more complete map of the world around the robot. One could also look to include more laser sensors to map behind and to either side of the robot. This should facilitate with the creation of a more complete motion plan without the need for the robot to map it first.
When implementing this type of project on real hardware, the mobile nature of a robot, requiring it also to contain its own power sources, means that efficient usage of a CPU and GPU are a must. The higher the utilisation, the less effective time the robot will have to perform activities.
Thus whilst implementing more sensors may provide a more detailed and accurate map, in the field this would further drain the power source. Hence careful consideration is needed for the number of sensors, the total power consumption of the sensors and compute work loads, as well as the impact the quantity of data has to the compute utilisation rates whilst mobile.
If there no significant improvement in performance for the design objective and operational goals of the robot, then a more minimalist sensor and localisation cost map configuration may be appropriate.
The first project in term 2 of the Udacity Robotics Nano Degree program requires students to initiate their own inference project inclusive of data acquisition. The project builds on the initial reference project for digit image recognition inside the supplied Nvidia Digits environment.
The project ideas are the student’s own and must have at least 3 classification categories eg defective item vs normal item with classes (no item, defective item, normal item).
Introduction
Pedestrian and bicycle lanes are often crowded with many people not aware of or selectively ignoring the signage. It can lead, to an unsafe or hazardous environment, for all that use it with police officers reluctant to enforce the rules via fines.
The concept selected, in this project, was to classify an image as either containing a pedestrian, not-pedestrian or background.
The goal being, that some sought of visual representation via a screen with a smile or a frown, could be given to act, as a robotic traffic controller. Other potential instantiation could include a torso using upper body movement to signal good or bad behaviour.
Background / Formulation
During the initial inference task, on supplied data, GoogLeNet was chosen as it had a good inference rate per image with reasonable accuracy. Using the Adam Optimiser with an initial learning rate of .001, it was able to meet the numerical requirements of inference time below 10 ms with accuracy > 75%. The input used for this reference model in Nvidia’s DIGITS was 256×256 3 channel colour images.
Similar requirements of accuracy would be required for this inference project. It was not necessary to be a 100% accurate as a smiling or frowning face at least makes people think about what they are presently doing. It was not going to be used to issue fines or other enforcement notices. Video cameras would stream image data between 24-30fps which means that an Inception, VGG model and some ResNet models may be too slow for inference in real time.
With the additional perception that colour could also be useful in detecting pedestrian vs not-pedestrian, GoogLeNet was again chosen for this project using the Adam Optimiser with an initial learning rate of .001.
Other experimentation with using a higher initial learning rate of 0.01 with the above configuration over 5 epochs did not improve validation accuracy which remained around 50%. Similarly AlexNet over 5 epochs with the same Adam optimiser and learning rate did not increase accuracy. One experiment was performed using GoogLeNet with RMSProp optimiser and an initial learning rate 0.001 which did not result in improvement of validation accuracy but did have significantly higher training loss so was also not progressed.
Data Acquisition
A GoPro mounted on a tripod was used. It was positioned on the side of a pedestrian esplanade at Surfers Paradise, Gold Coast, Australia. As it was summer holidays a reasonable amount of varying traffic was expected. The background looked over the ocean to have a consistent image where there was not going to be movement (besides cloud) other then what was on the esplanade.
GoPro Data Acquisition
Three angles (facing left, centre and right) were used for capture per the following graphic:
Camera Background Angles
The GoPro was setup in wifi mode for time lapse capture, which was controlled via an iPhone. Initially 2 seconds elapsed was used, which eventually was dropped to 0.5. Using the GoPro time-lapse feature, meant that individual jpeg files were captured as opposed to a MP4 video.
Using the iPhone to control the control, meant that I could visualise what was coming before starting the next capture batch.
After the capture the images were manually placed into a directory for each category.
Image data was captured for the three categories background (322), pedestrian (349) and not-pedestrian (94). It became apparent at this time that not enough not-pedestrian image data had been captured. This was mainly due to the initial 2 seconds elapsed time used. Due to high heat and humidity of the Australian summer, in the following afternoons, it was not practical to capture more data from the same spot.
Skateboarders were placed in the pedestrian category.
An example of a pedestrian and not-pedestrian follows. Background examples are as above.
not-pedestrian examplepedestrian example
A jupyter notebook was used to create a generator to supplement the data by randomising the image brightness, randomly flipping the images vertically and jittering the images randomly
in the x (by or – 25 pixels),y (by or – 50 pixels) planes to create supplemental image data.
The images were also resized to 256 x 256 and saved as PNGs.
The final generated supplemental data had 2000 not-pedestrian, 1000 pedestrian with 1000 background images.
Results
The initial inference task, on supplied data, GoogLeNet was chosen as it had a good inference rate per image with reasonable accuracy. Using the Adam Optimiser with an initial learning rate of .001, it was able to meet the numerical requirements of inference time below 10 ms (~5 ms actual) with accuracy > 75% (75.40984% actual).
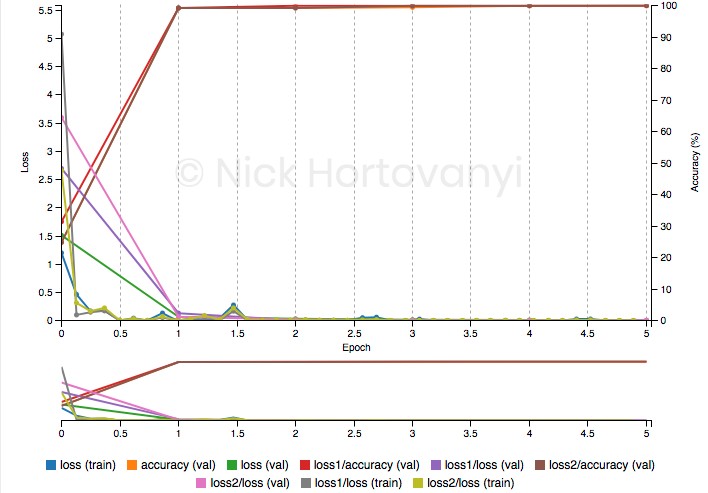
During training of the initial inference task 100% validation was achieved per the following training graph after 5 epochs.
Training Graph
However similar training results were not achieved for this inference project on captured data. The following training graph after 10 epochs follows
Project Training Graph
This had a validation accuracy of ~50%.
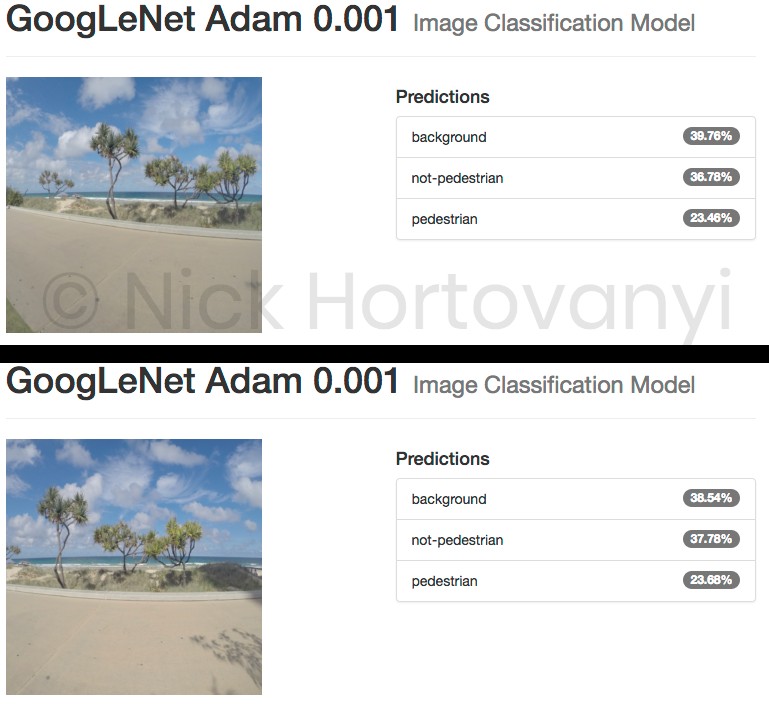
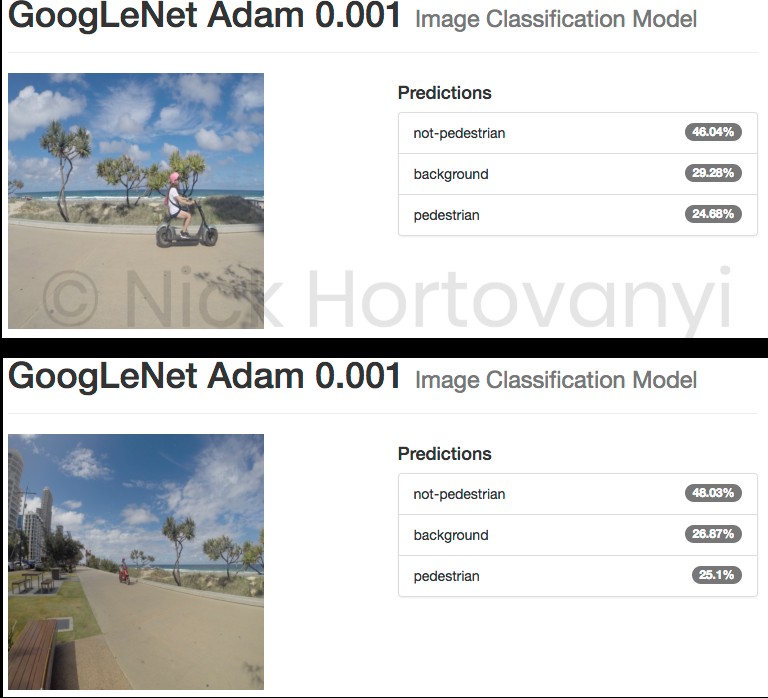
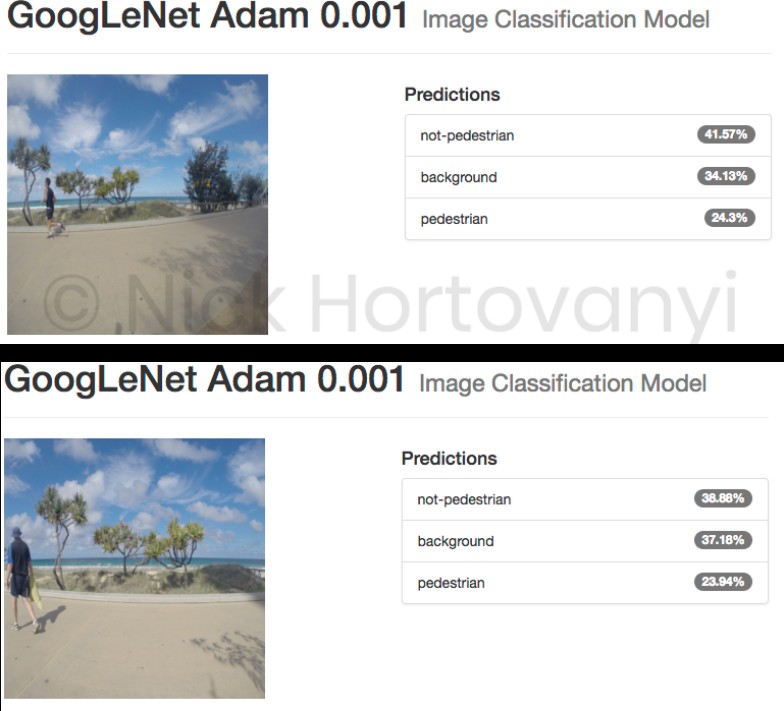
The following are the results of two randomly selected images per classification category uploaded as original high-res jpeg images from the GoPro.
The indicative inspection suggests that there was insufficient data to get a result > 75% for this project at this time. It also appears that the model as trained can not distinguish between pedestrian and not-pedestrian but can distinguish a background image.
Inference times were not tested separately as GoogLeNet is known to have a fast inference time which would be sufficient for this project.
Discussion
The dataset collected did not have enough sample images. This was as a result of using time-lapse with too high a value. In hind site, a combination of 0.5-1 sec time-lapse for slow moving pedestrians with >30 FPS video for higher speed moving non-pedestrians would of allowed for more data.
Of note is when there is a combination of non-pedestrian and pedestrian in the same frame led to the though of potentially using object detection first to find a window to classify. This was not implemented in this version however it would have led to a more accurate ability to classify as the background would be eliminated ie if no objects detected it must be a back ground image.
For this project the duration of a consistent display of say 2 to 3 seconds to the passing pedestrian and non-pedestrian traffic would drive the ultimate inference time required. It would suggest that it needs to be an average classification of a 1 second or two when leading up to where the video is captured.
Of note were skateboarders. There is only the skateboard (which has a low profile in the image) that distinguishes it from a pedestrian as velocity is not taken account with single images.
In addition the depth (away from the camera) of the traffic passing by changes the size of the object that needs to be classified. Pre-filtering and zooming these to a consistent size may improve accuracy.
Future Work
Whilst the project did not achieve a good train validation result, it has laid the foundation for future iterations. There is potential to capture more data and use object detection to refine the training and inference steps of the project.
Providing soft means to monitor and influence peoples decisions regarding signage and the associated rules for safe usage of (non-vehicle) transit paths would potentially be received positively by the community. Police forces lack the budget or people to enforce these rules and they are reluctant to issue minor infringement notices (with potential to destroy good will in the community). Hence a more subtle robotic person could improve the situation in a cost effective means.
The size of this market is unknown. However speed cameras using smiley and sad faces are used around the local area where I live. They are having a positive impact on driver behaviour in the areas deployed. Thus there is a market for a more community friendly and automated means to impact on behaviour.
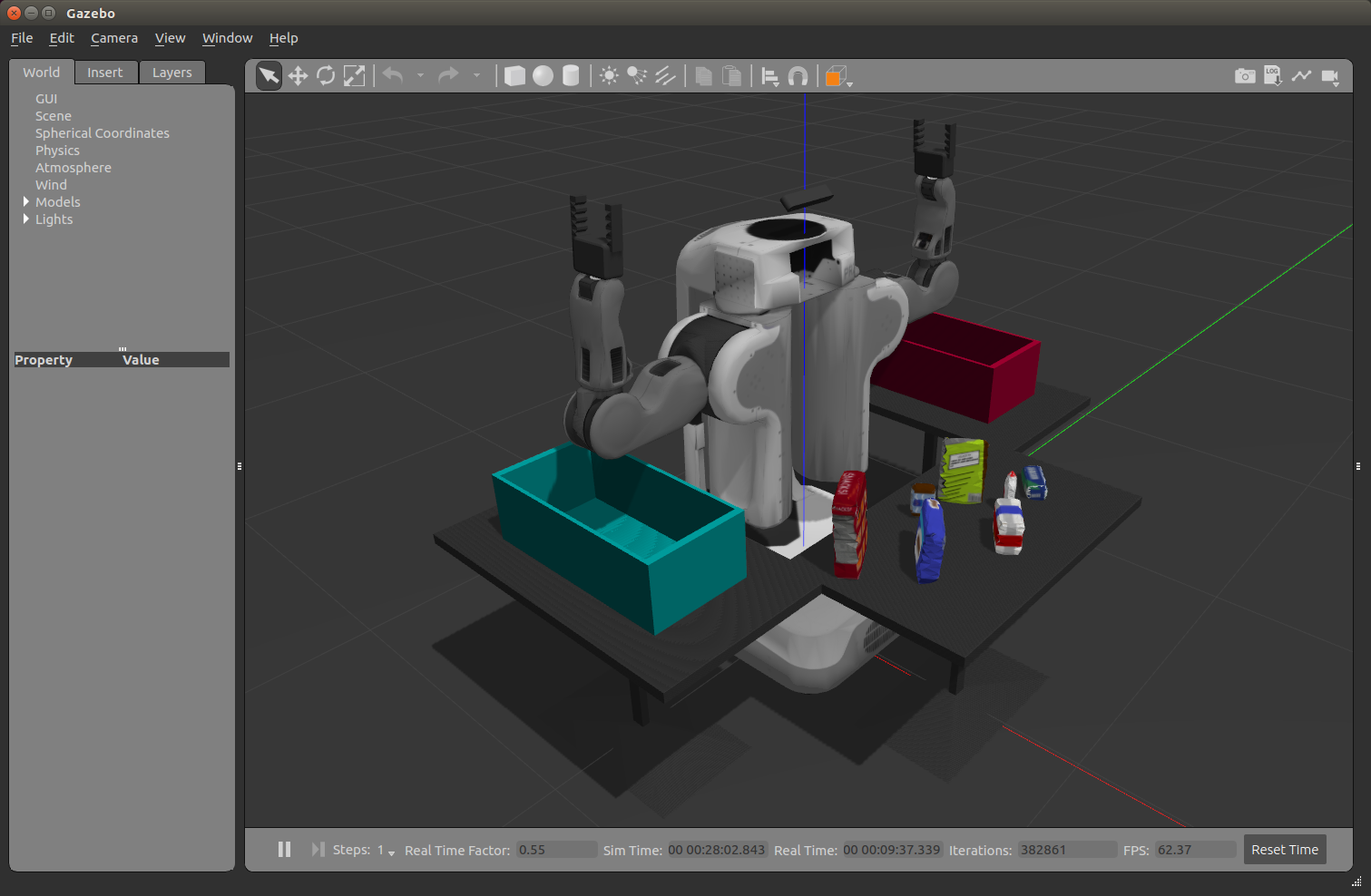
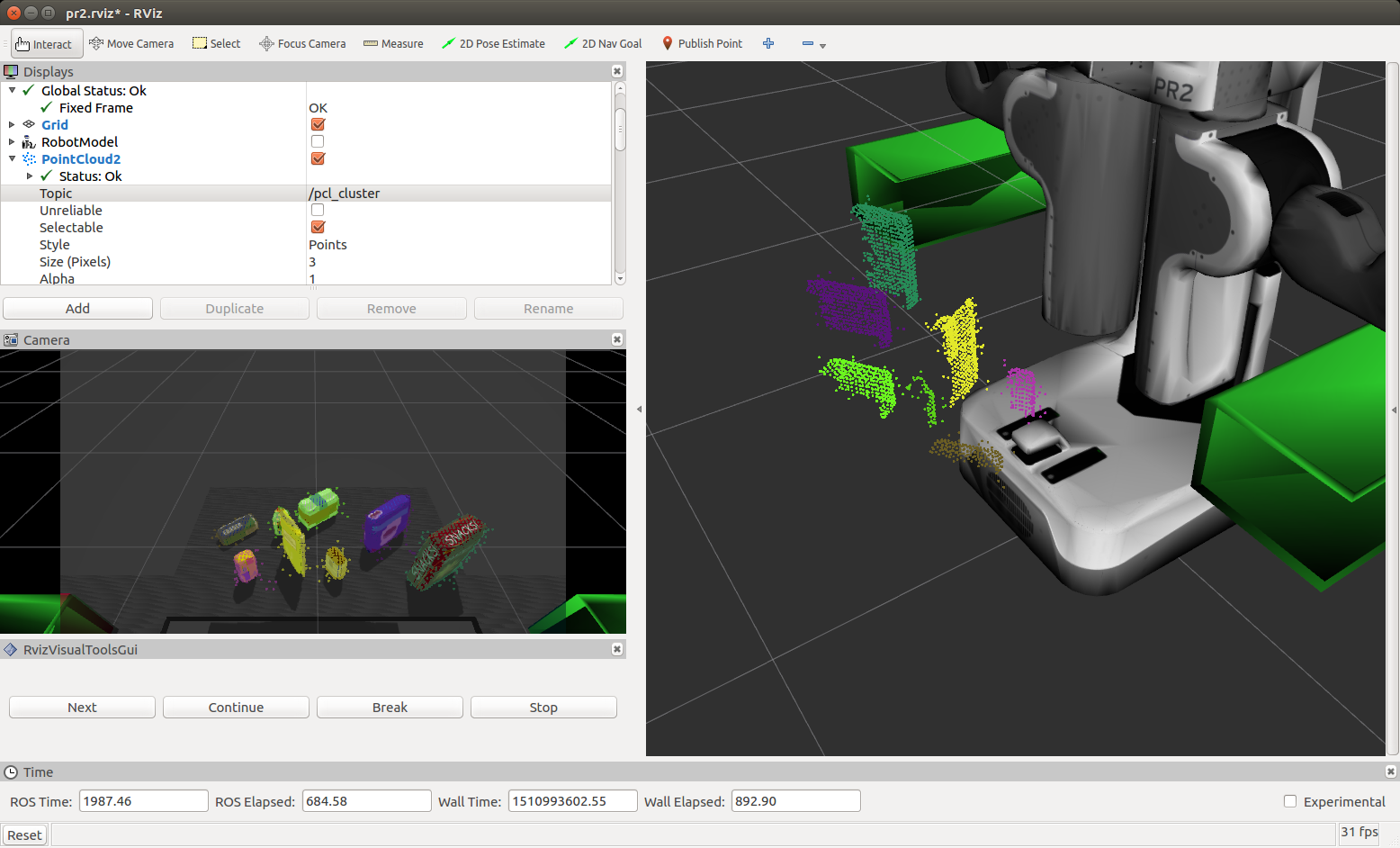
Complete Exercise 1 steps. Pipeline for filtering and RANSAC plane fitting implemented.
The 3D perception pipeline begins with a noisy pc2.PointCloud2 ROS message. A sample animated GIF follows:
Noisy Camera Cloud
After conversion to a PCL cloud a statistical outlier filter is applied to give a filtered cloud.
The cloud with inlier ie outliers filtered out follows:
Cloud Inlier Filtered
A voxel filter is applied with a voxel (also know as leaf) size = .01 to down sample the point cloud.
Voxel Downsampled
Two passthrough filters one on the ‘x’ axis (axis_min = 0.4axis_max = 3.) to remove the box edges and another on the ‘z’ axis (axis_min = 0.6axis_max = 1.1) along the table plane are applied.
Passthrough Filtered
Finally a RANSAC filter is applied to find inliers being the table and outliers being the objects on it per the following
# Create the segmentation object
seg = cloud_filtered.make_segmenter()
# Set the model you wish to fit
seg.set_model_type(pcl.SACMODEL_PLANE)
seg.set_method_type(pcl.SAC_RANSAC)
# Max distance for a point to be considered fitting the model
max_distance = .01
seg.set_distance_threshold(max_distance)
# Call the segment function to obtain set of inlier indices and model coefficients
inliers, coefficients = seg.segment()
# Extract inliers and outliers
extracted_inliers = cloud_filtered.extract(inliers, negative=False)
extracted_outliers = cloud_filtered.extract(inliers, negative=True)
cloud_table = extracted_inliers
cloud_objects = extracted_outliers
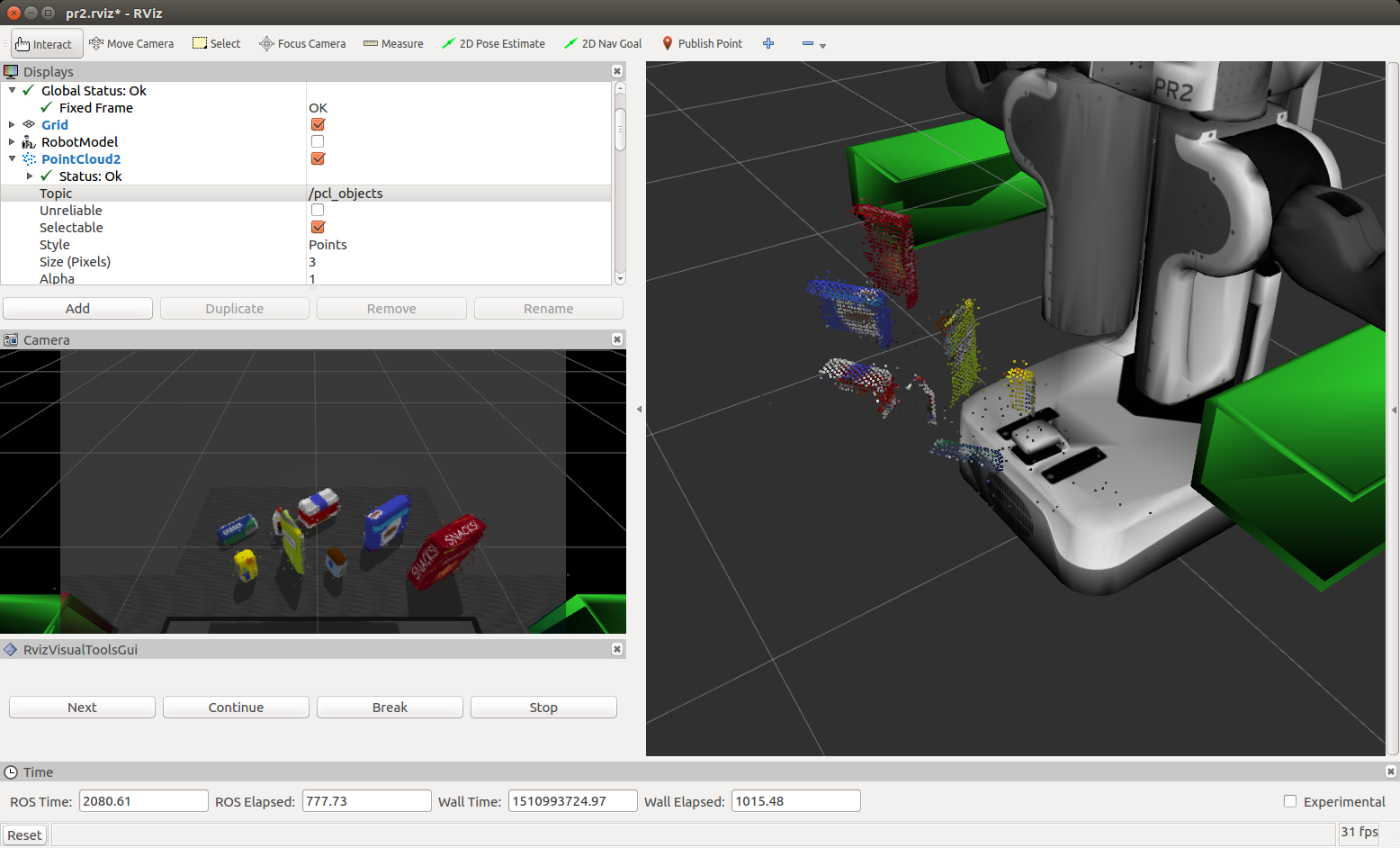
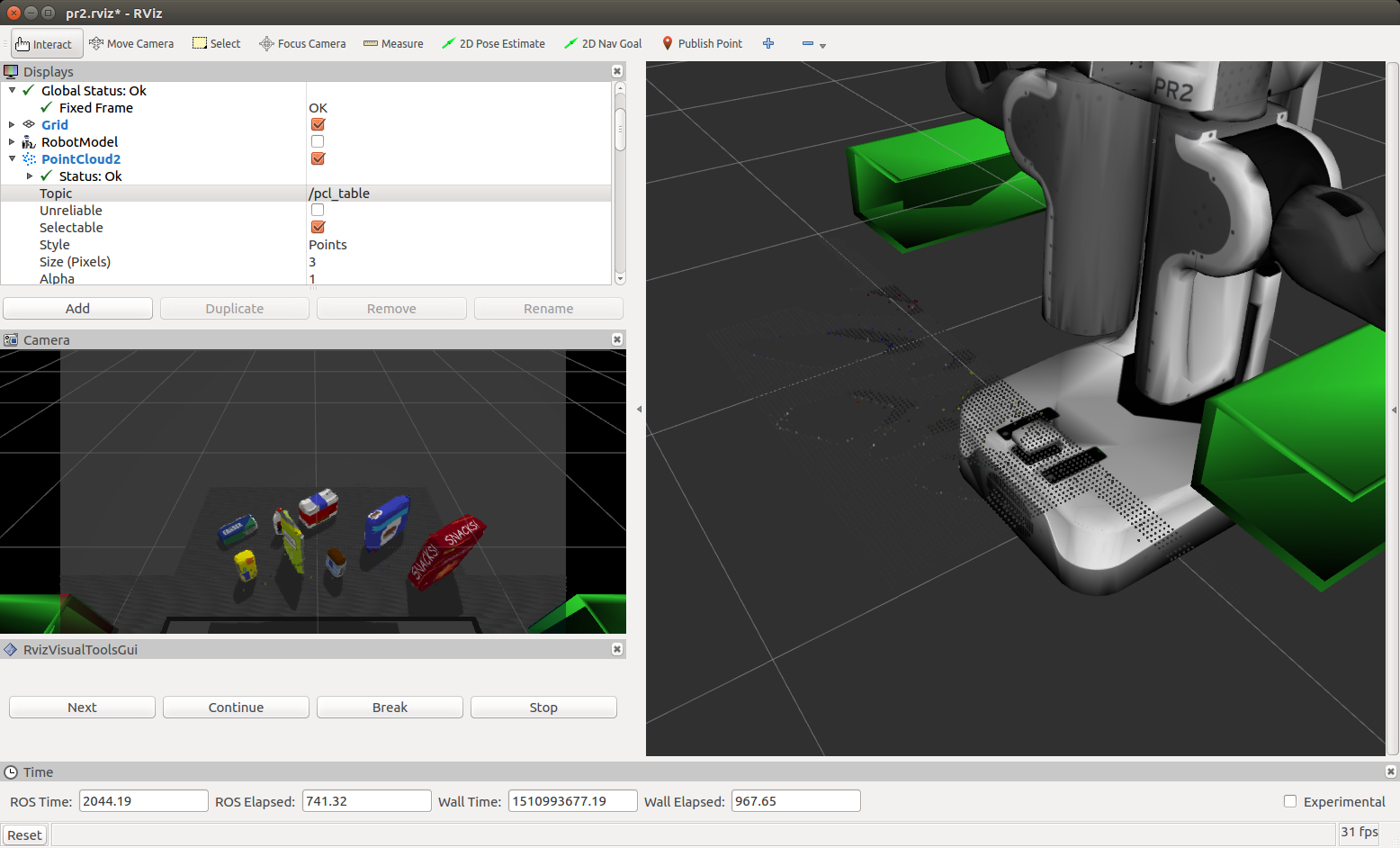
Complete Exercise 2 steps: Pipeline including clustering for segmentation implemented.
Euclidean clustering on a white cloud is used to extract cluster indices for each cluster object. Individual ROS PCL messages are published (for the cluster cloud, table and objects) per the following code snippet:
# Euclidean Clustering
white_cloud = XYZRGB_to_XYZ(cloud_objects)
tree = white_cloud.make_kdtree()
# Create a cluster extraction object
ec = white_cloud.make_EuclideanClusterExtraction()
# Set tolerances for distance threshold
# as well as minimum and maximum cluster size (in points)
ec.set_ClusterTolerance(0.03)
ec.set_MinClusterSize(30)
ec.set_MaxClusterSize(1200)
# Search the k-d tree for clusters
ec.set_SearchMethod(tree)
# Extract indices for each of the discovered clusters
cluster_indices = ec.Extract()
# Create Cluster-Mask Point Cloud to visualize each cluster separately
#Assign a color corresponding to each segmented object in scene
cluster_color = get_color_list(len(cluster_indices))
color_cluster_point_list = []
for j, indices in enumerate(cluster_indices):
for i, indice in enumerate(indices):
color_cluster_point_list.append([white_cloud[indice][0],
white_cloud[indice][1],
white_cloud[indice][2],
rgb_to_float(cluster_color[j])])
#Create new cloud containing all clusters, each with unique color
cluster_cloud = pcl.PointCloud_PointXYZRGB()
cluster_cloud.from_list(color_cluster_point_list)
# Convert PCL data to ROS messages
ros_cloud_objects = pcl_to_ros(cloud_objects)
ros_cloud_table = pcl_to_ros(cloud_table)
ros_cluster_cloud = pcl_to_ros(cluster_cloud)
# Publish ROS messages
pcl_objects_pub.publish(ros_cloud_objects)
pcl_table_pub.publish(ros_cloud_table)
pcl_cluster_pub.publish(ros_cluster_cloud)
/pcl_objects/pcl_table/pcl_cluster
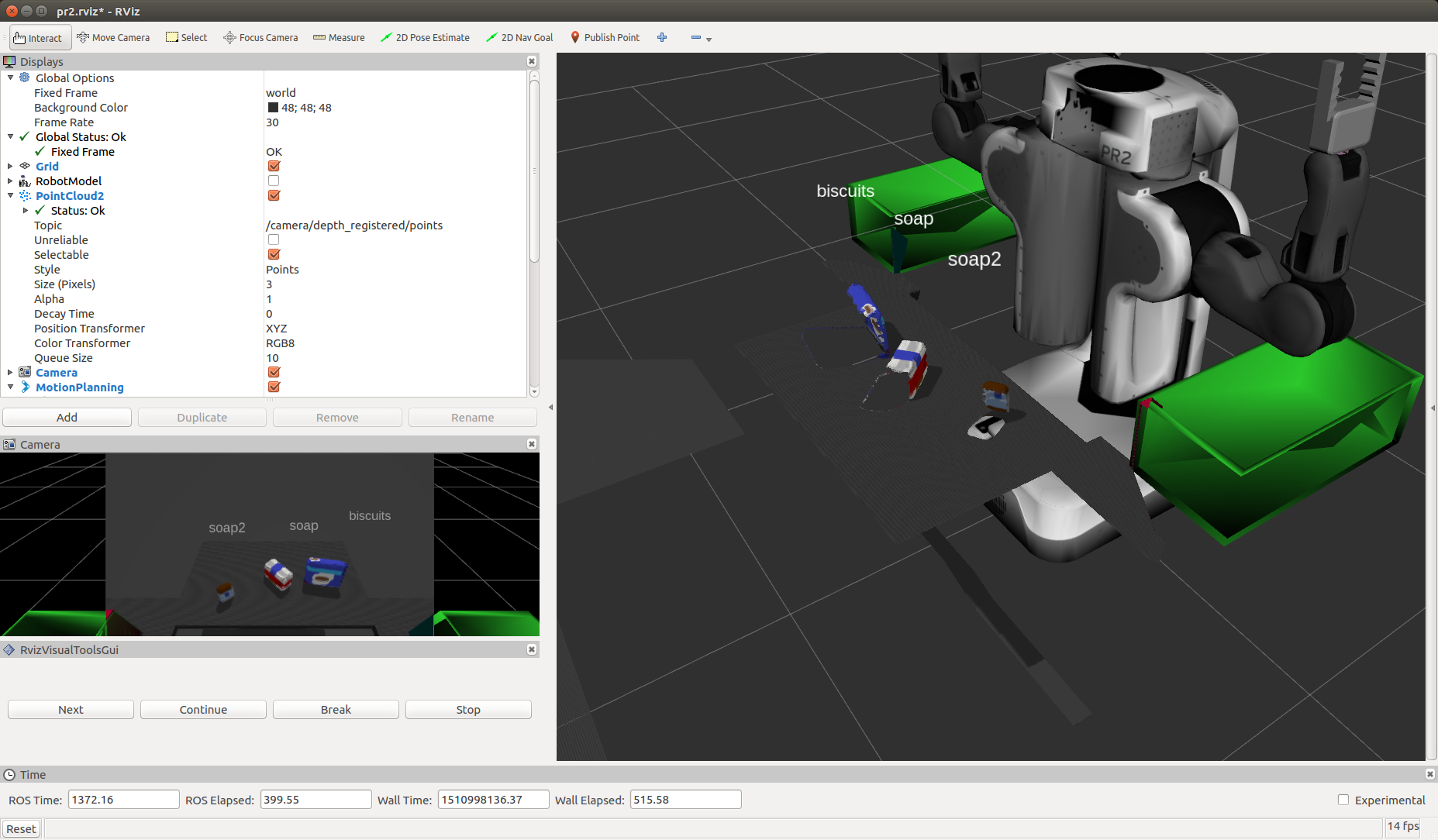
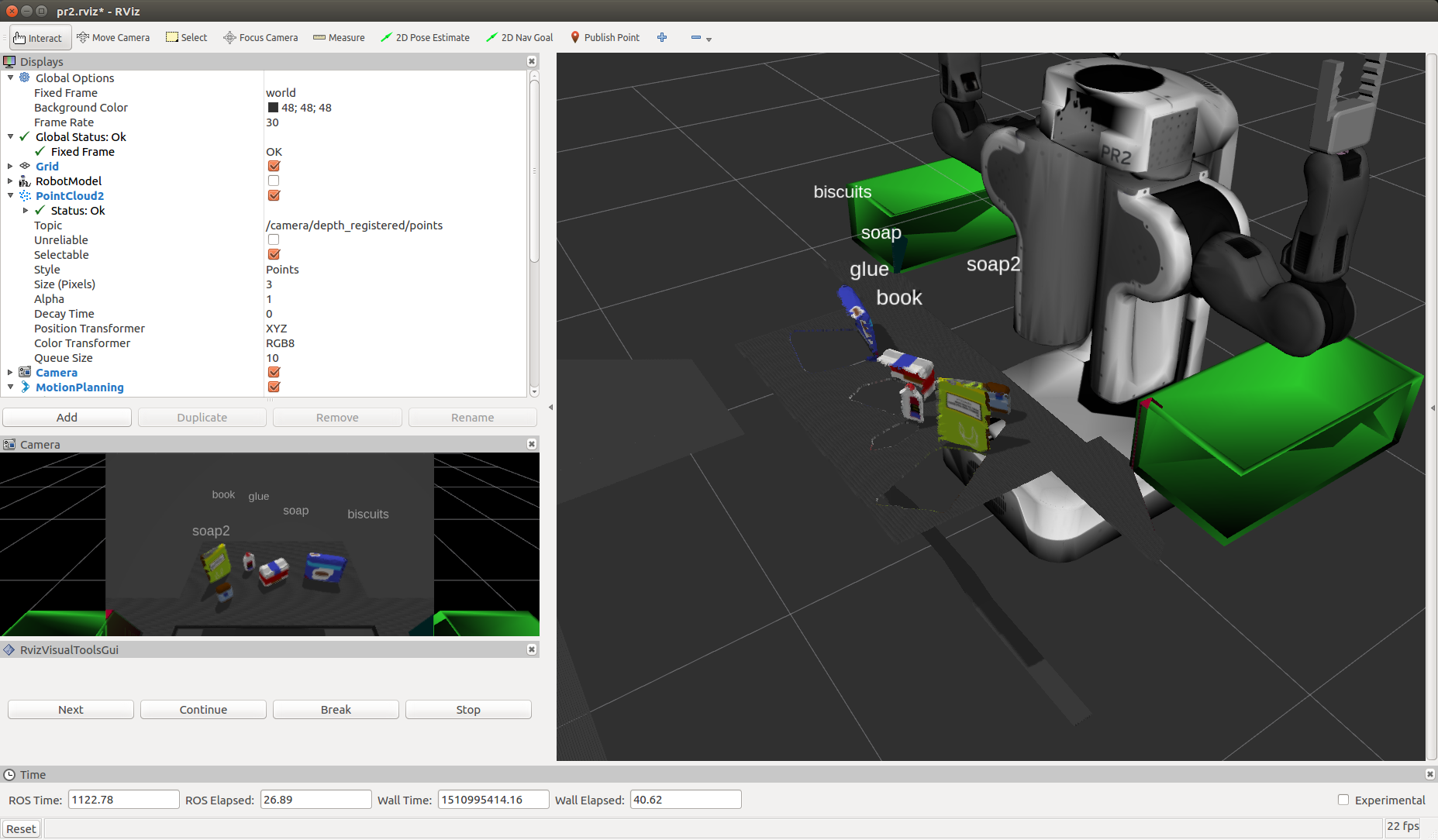
Complete Exercise 3 Steps. Features extracted and SVM trained. Object recognition implemented.
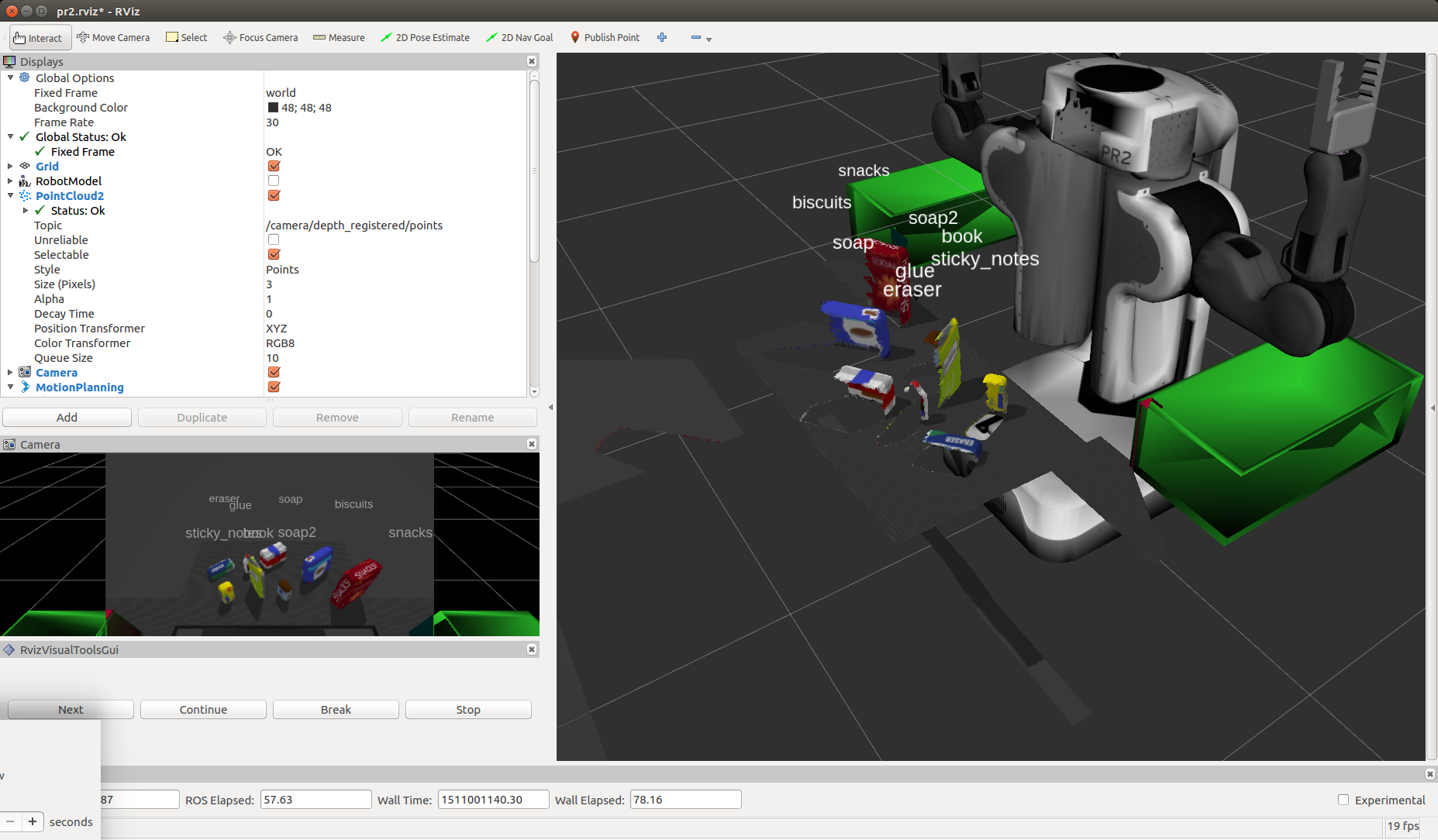
Features were captured in the sensor_stick simulator for [‘biscuits’, ‘soap’, ‘soap2’, ‘book’, ‘glue’, ‘sticky_notes’, ‘snacks’, ‘eraser’] model names with 40 sample of each captures.
hsv color space was used a combination of color and normalised histograms per
The colour histograms where produced with 32 bins in the range (0, 256) and the normal values with 32 bins in the range (-1, 1.).
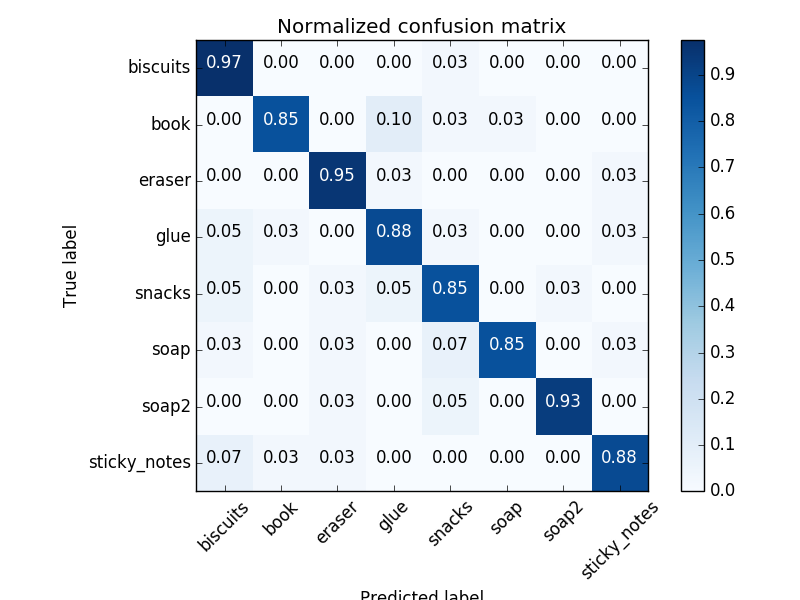
The full training.set was used in train_svm.py where I replaced the standard sum.SVC(kernel='linear') classifier with a Random Forest based classifier.
It dramatically improved training scores per the following normalised confusion matrix:
normalised confusion matrix
The trained model.sav was used as input into the perception pipeline where for each cluster found in the point cloud, histogram features were extracted as per the training step above and used in prediction and added to a list of detected objects.
# Make the prediction, retrieve the label for the result
# and add it to detected_objects_labels list
prediction = clf.predict(scaler.transform(feature.reshape(1, -1)))
label = encoder.inverse_transform(prediction)[0]
It was interesting to learn about using point clouds and to learn this approach. I found occasionally there was some false readings. In addition few of the objects were picked and placed in the crates (the PR2 did not seem to grasp them properly). This may mean that further effort is needed to refine the centroid selection of each object.
Whilst I achieved average ~90% accuracy, across all models, on the classifier training, with more time spent, I would have liked to have achieved closer to 97%. This would also improve those false readings. I’m also not sure I fully understand the noise introduced in this project from the PR2 RGBD camera.
If I was to approach this project again, I’d be interested to see how a 4D Tensor would work via deep learning using YOLO and/or CNNs. Further research is required.