In this vehicle detection and tracking project, we detect in a video pipeline, potential boxes, via a sliding window, that may contain a vehicle by using a Support Vector Machine Classifier for prediction to create a heat map. The heat map history is then used to filter out false positives before identification of vehicles by drawing a bounding box around it.

Vehicle Detection Project
The goals / steps of this project are the following:
- Perform a Histogram of Oriented Gradients (HOG) feature extraction on a labeled training set of images and train a classifier Linear SVM classifier
- Optionally, you can also apply a color transform and append binned color features, as well as histograms of color, to your HOG feature vector.
- Note: for those first two steps don’t forget to normalize your features and randomize a selection for training and testing.
- Implement a sliding-window technique and use your trained classifier to search for vehicles in images.
- Run your pipeline on a video stream (start with the test_video.mp4 and later implement on full project_video.mp4) and create a heat map of recurring detections frame by frame to reject outliers and follow detected vehicles.
- Estimate a bounding box for vehicles detected.
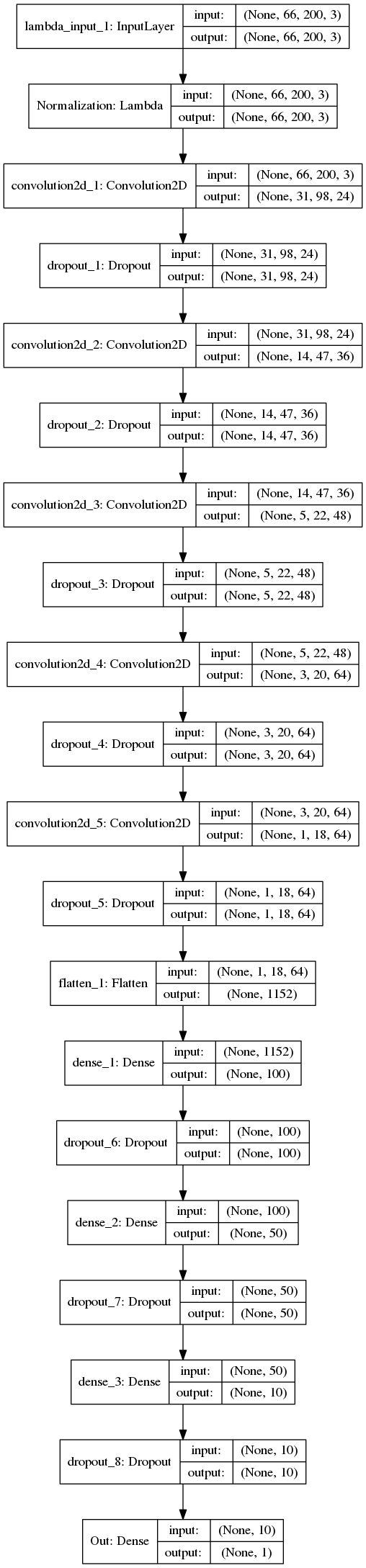
A jupyter/iPython data science notebook was used and can be found on github Full Project Repo – Vehicle Detection Project Notebook (Note the interactive ipywidgets are not functional on github). As the notebook got rather large I extracted some code into python files utils.py (functions to extract, loading helpers), features.py (feature extraction and classes), images.py (image and window slice processing), search.py (holds search parameters class), boxes.py (windowing and box classes) and detection.py (main VehicleDetection class that coordinates processing of images). The project is written in python and utilises numpy, OpenCV, scikit learn and MoviePy.
Histogram of Oriented Gradients (HOG)
Through a bit of trial and error I found a set of HOG parameters.
HOG Feature Extraction and Parameters
A function extract_hog_features was created that took an array of 64x64x3 images and returned a set of features. These are extracted in parallel and it in turn uses HogImageFeatures class.
As the hog algorithm is primarily focused on grey images, I initially used the YCrCB colour space with the Y channel (used to represent a gray images). However I found that it was not selective enough during the detection phase. I thus used all 3 colour channels. To reduce the number of features, I increased the number of HOG pixels per cell. I used an interactive feature in my notebook to find an orient setting of 32 that showed distinctive features of vehicle. Sample follows.

The final parameter settings used color_space = 'YCrCb',orient = 32,pix_per_cell = 16 and hog_channel = 'ALL'. Experimentation occurred with using Colour Histogram Features but it slowed down feature extraction and later increased the number of false positives detected. Per the following visualisation graphic, you can see that the Cr and Cb colour spaces had detectable hog features

Classifier Training
Once HOG features (no Colour Hist or Bin Spatial) were extracted from car (GTI Vehicle Image Database and Udacity Extras) and not_car (GTI, KITTI) image sets. They were then stacked and converted to float in the vehicle detection notebook.
Features were then scaled using the Sklearn RobustScaler sample result follows.

Experimentation occurred in the Classifier Experimentation Notebook between LinearSVC (Support Vector Machine Classifier), RandomForest and ExtraTrees classifiers. LinearSVC was chosen as the prediction time was 0.00228 seconds for 10 labels compared to ~0.10 seconds for the other two.
Sliding Window Search
Building sliding windows
For this project four sizes of windows were chosen – 32×32, 48×48, 64×64 and 128×128 and position at different depth perspective on the bottom right side of the image to cover the road. The larger windows closer to the driver and the smaller closer to the horizon. Overlap in both x,y was set between 0.5 and 0.8 to balance the need for better coverage vs number of boxes generated – currently 937. The more boxes for a sliding window, the more calculations per video image.
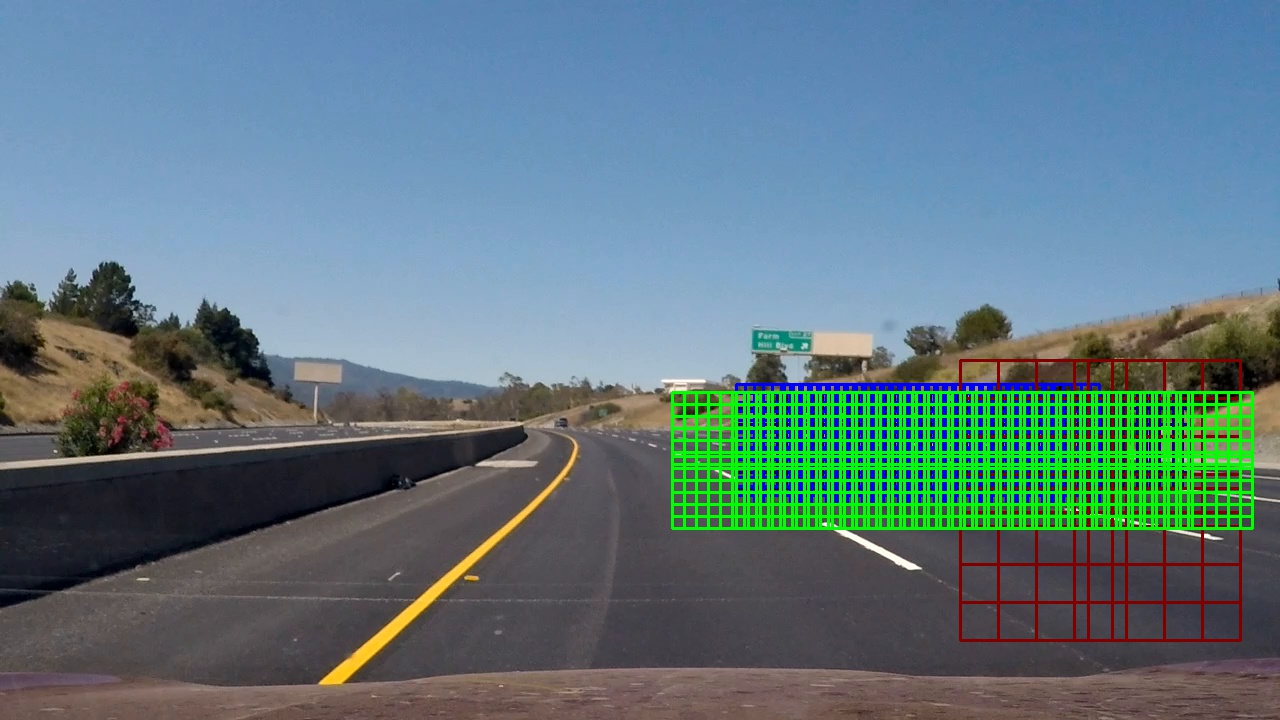
Classifier examples and optimisation
Some time was spent on parallelisation of the search using Python async methods and asyncio.gather in the VehicleDetection class. The search extracts the bounded box image of each sized search window and scales it to 64×64 before doing feature extraction and prediction on each window.

The search hot_box_search returns an array of hot boxes that classifier has predicted contains a vehicle.
These boxes overlap and are used to create a clipped at 255, two dimensional heat map. To remove initial false positives counts > 4 are kept. The heat map is then normalised before another threshold is applied
heatmap = apply_threshold(heatmap, 4)
heatmap_std = heatmap.std(ddof=1)
if heatmap_std != 0.0:
heatmap = (heatmap-heatmap.mean())/heatmap_std
heatmap = apply_threshold(heatmap, np.max([heatmap.std(), 1]))
Plotting this stage back onto the image

A history is kept of heat maps  which is then used as input into Scipy Label with a dim binary structure linking dimensions, giving
which is then used as input into Scipy Label with a dim binary structure linking dimensions, giving
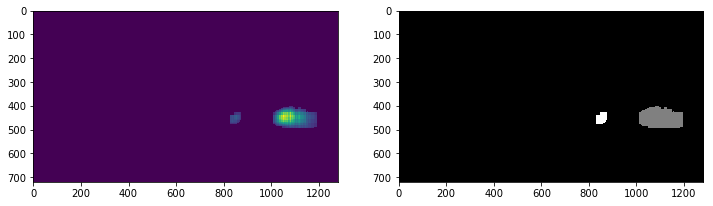
finally a variance filter is applied on each box, if for one detected label boxes are ignored with a variance < 0.1 (its just a few close points0 or if multiple with a variance < 1.5 (more noise).
Video Implementation
Vehicle Detection Video
The Project VehicleDetection mp4 on GitHub, contains the result (YouTube Copy)

Tracking Vehicle Detections
One of the nice features of the scipy.ndimage.measurements.label function is that it can process 3d arrays giving labels in x,y,z spaces. Thus when using the array of heat map history as input, it labels connections in x,y,z. If a returned label box is not represented in at least 3 (heat map history max – 2) z planes then it is rejected as a false positive. The result is that a vehicle is tracked over the heat map history kept.
Discussion
When construction this pipeline, I spent some time working on parallelising the window search. What I found is that there is most likely little overall performance improvement to be gained by doing so. Images have to be processed in series and whilst generating the video, my cpu was under utilised.
In hindsight I should of used a heavy weight search to detect vehicles and then a more lighter weight, narrower search primed by the last known positions. Heavy weight searching could be run at larger intervals or when a vehicle detection is lost.
My pipeline would fail presently if vehicles were on the left hand side or centre of the car. I suspect trucks, motorbikes, cyclists and pedestrians would not be detected (as they are not in the training data).





{kind=link}