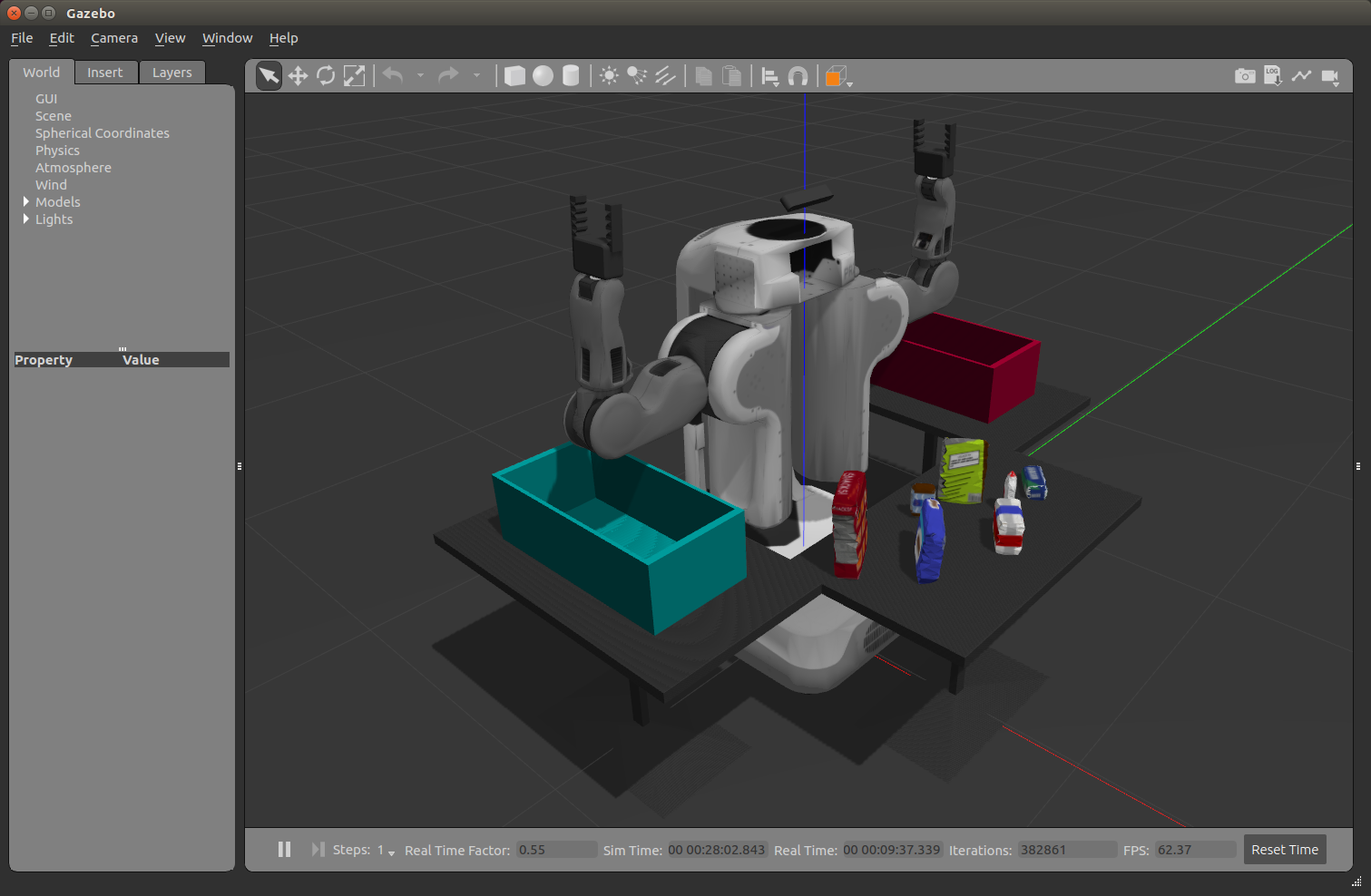
The goal of this project was to create a 3D Perception Pipeline to identify and label the table objects using the PR2 RGBD (where D is Depth) camera.
Exercise 1, 2 and 3 Pipeline Implemented
For this project the combined pipeline was implemented in perception_pipeline.py
Complete Exercise 1 steps. Pipeline for filtering and RANSAC plane fitting implemented.
The 3D perception pipeline begins with a noisy pc2.PointCloud2 ROS message. A sample animated GIF follows:

After conversion to a PCL cloud a statistical outlier filter is applied to give a filtered cloud.
The cloud with inlier ie outliers filtered out follows:

A voxel filter is applied with a voxel (also know as leaf) size = .01 to down sample the point cloud.

Two passthrough filters one on the ‘x’ axis (axis_min = 0.4 axis_max = 3.) to remove the box edges and another on the ‘z’ axis (axis_min = 0.6 axis_max = 1.1) along the table plane are applied.
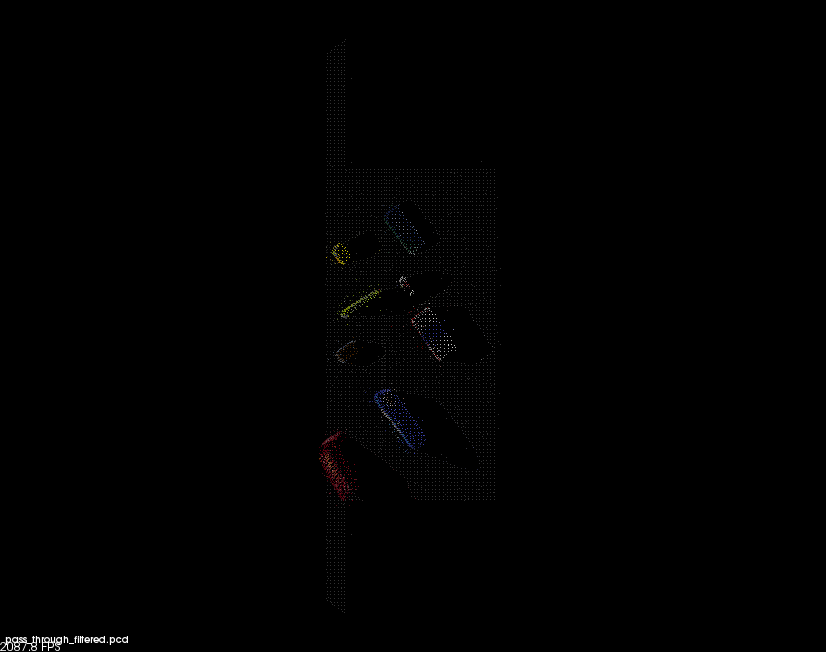
Finally a RANSAC filter is applied to find inliers being the table and outliers being the objects on it per the following
# Create the segmentation object
seg = cloud_filtered.make_segmenter()
# Set the model you wish to fit
seg.set_model_type(pcl.SACMODEL_PLANE)
seg.set_method_type(pcl.SAC_RANSAC)
# Max distance for a point to be considered fitting the model
max_distance = .01
seg.set_distance_threshold(max_distance)
# Call the segment function to obtain set of inlier indices and model coefficients
inliers, coefficients = seg.segment()
# Extract inliers and outliers
extracted_inliers = cloud_filtered.extract(inliers, negative=False)
extracted_outliers = cloud_filtered.extract(inliers, negative=True)
cloud_table = extracted_inliers
cloud_objects = extracted_outliers
Complete Exercise 2 steps: Pipeline including clustering for segmentation implemented.
Euclidean clustering on a white cloud is used to extract cluster indices for each cluster object. Individual ROS PCL messages are published (for the cluster cloud, table and objects) per the following code snippet:
# Euclidean Clustering
white_cloud = XYZRGB_to_XYZ(cloud_objects)
tree = white_cloud.make_kdtree()
# Create a cluster extraction object
ec = white_cloud.make_EuclideanClusterExtraction()
# Set tolerances for distance threshold
# as well as minimum and maximum cluster size (in points)
ec.set_ClusterTolerance(0.03)
ec.set_MinClusterSize(30)
ec.set_MaxClusterSize(1200)
# Search the k-d tree for clusters
ec.set_SearchMethod(tree)
# Extract indices for each of the discovered clusters
cluster_indices = ec.Extract()
# Create Cluster-Mask Point Cloud to visualize each cluster separately
#Assign a color corresponding to each segmented object in scene
cluster_color = get_color_list(len(cluster_indices))
color_cluster_point_list = []
for j, indices in enumerate(cluster_indices):
for i, indice in enumerate(indices):
color_cluster_point_list.append([white_cloud[indice][0],
white_cloud[indice][1],
white_cloud[indice][2],
rgb_to_float(cluster_color[j])])
#Create new cloud containing all clusters, each with unique color
cluster_cloud = pcl.PointCloud_PointXYZRGB()
cluster_cloud.from_list(color_cluster_point_list)
# Convert PCL data to ROS messages
ros_cloud_objects = pcl_to_ros(cloud_objects)
ros_cloud_table = pcl_to_ros(cloud_table)
ros_cluster_cloud = pcl_to_ros(cluster_cloud)
# Publish ROS messages
pcl_objects_pub.publish(ros_cloud_objects)
pcl_table_pub.publish(ros_cloud_table)
pcl_cluster_pub.publish(ros_cluster_cloud)
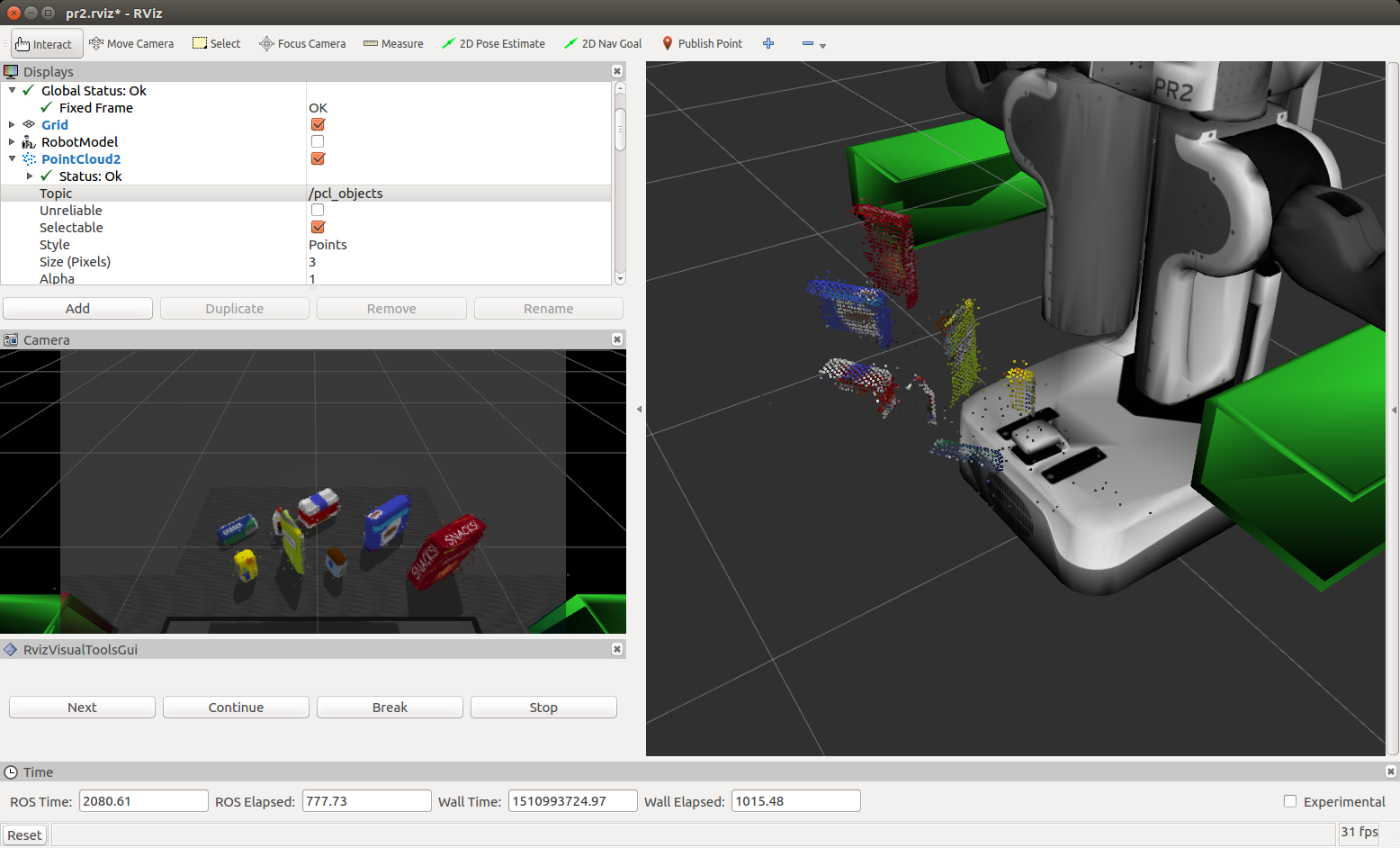
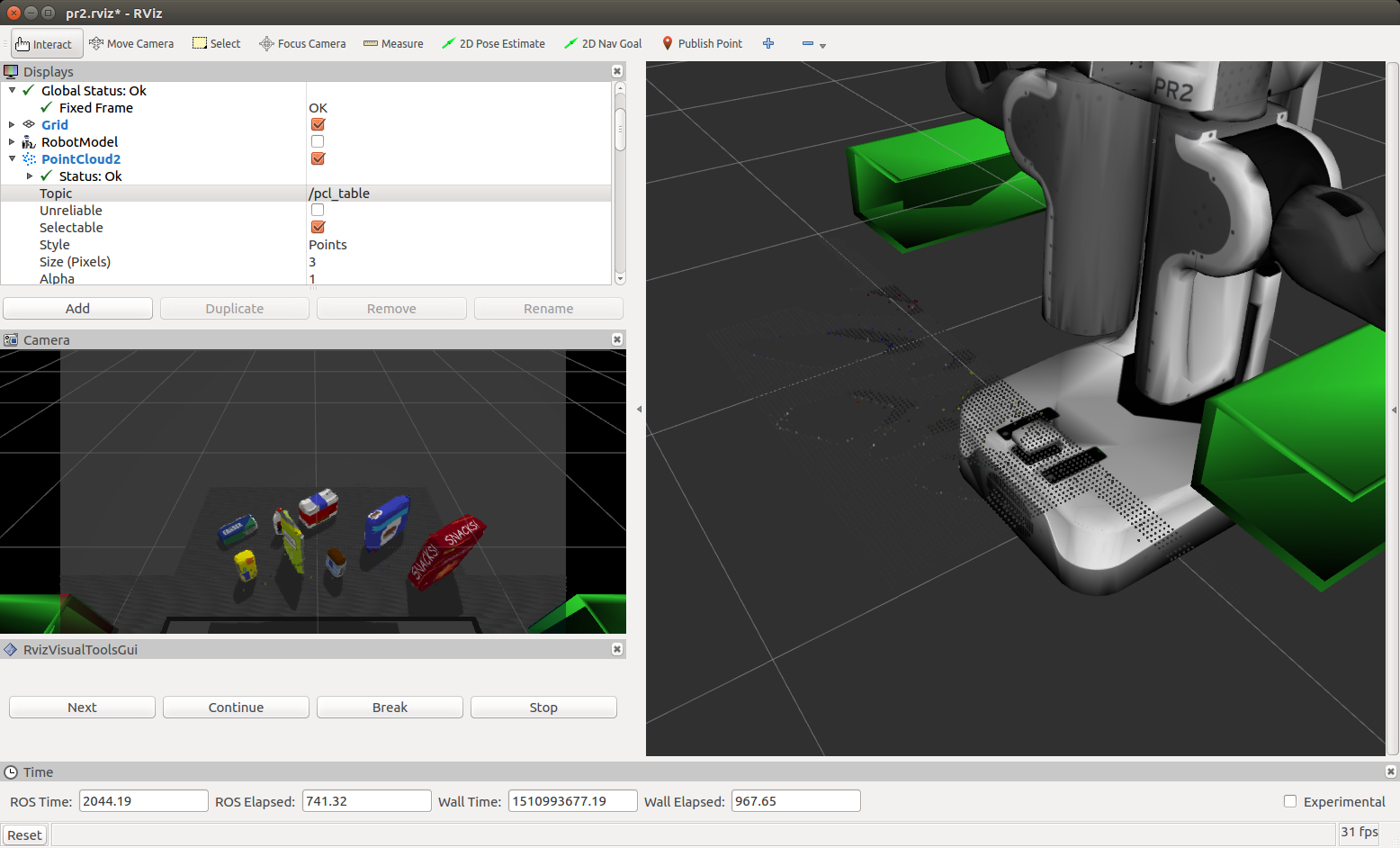
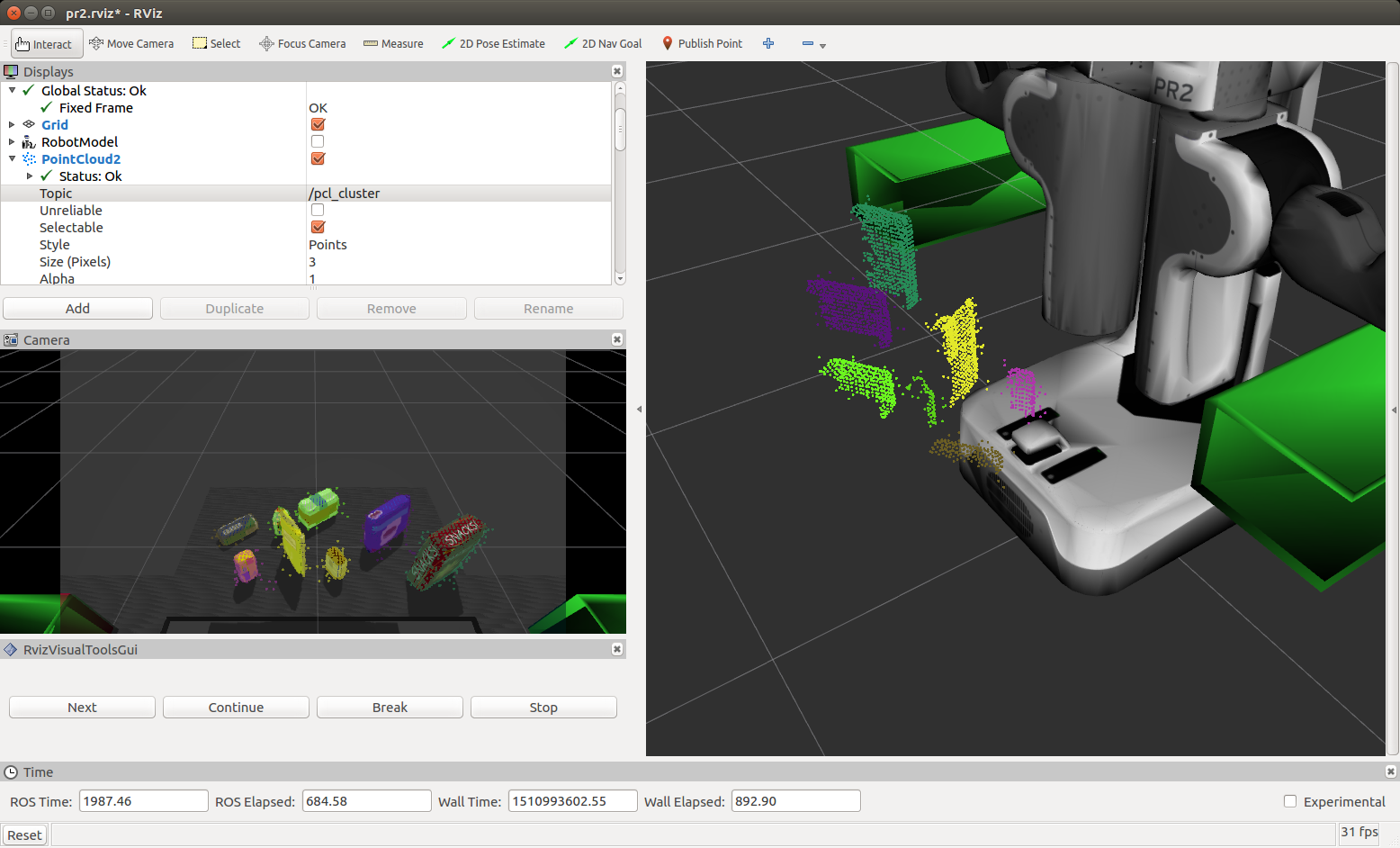
Complete Exercise 3 Steps. Features extracted and SVM trained. Object recognition implemented.
Features were captured in the sensor_stick simulator for [‘biscuits’, ‘soap’, ‘soap2’, ‘book’, ‘glue’, ‘sticky_notes’, ‘snacks’, ‘eraser’] model names with 40 sample of each captures.
hsv color space was used a combination of color and normalised histograms per
# Extract histogram features
chists = compute_color_histograms(sample_cloud, using_hsv=True)
normals = get_normals(sample_cloud)
nhists = compute_normal_histograms(normals)
feature = np.concatenate((chists, nhists))
labeled_features.append([feature, model_name])
The colour histograms where produced with 32 bins in the range (0, 256) and the normal values with 32 bins in the range (-1, 1.).
The full training.set was used in train_svm.py where I replaced the standard sum.SVC(kernel='linear') classifier with a Random Forest based classifier.
clf = ExtraTreesClassifier(n_estimators=10, max_depth=None,
min_samples_split=2, random_state=0)
It dramatically improved training scores per the following normalised confusion matrix:
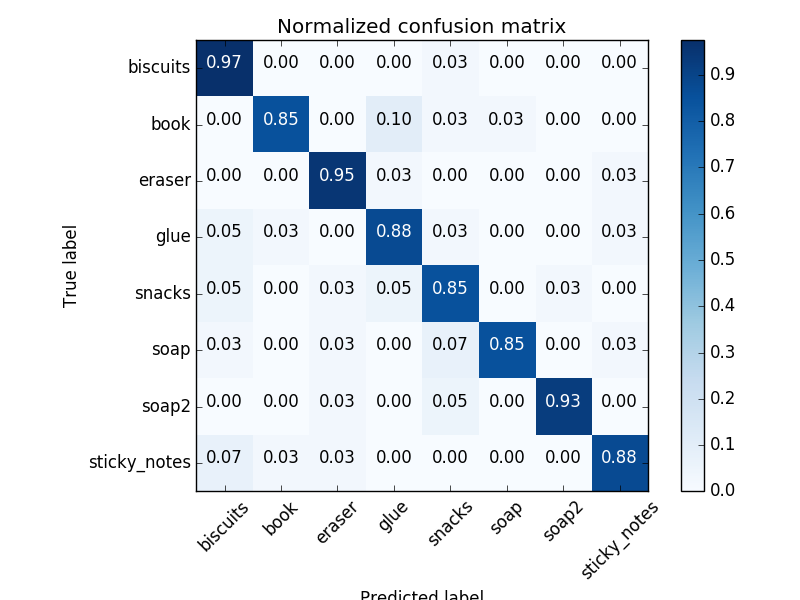
The trained model.sav was used as input into the perception pipeline where for each cluster found in the point cloud, histogram features were extracted as per the training step above and used in prediction and added to a list of detected objects.
# Make the prediction, retrieve the label for the result
# and add it to detected_objects_labels list
prediction = clf.predict(scaler.transform(feature.reshape(1, -1)))
label = encoder.inverse_transform(prediction)[0]
Pick and Place Setup
test1.world
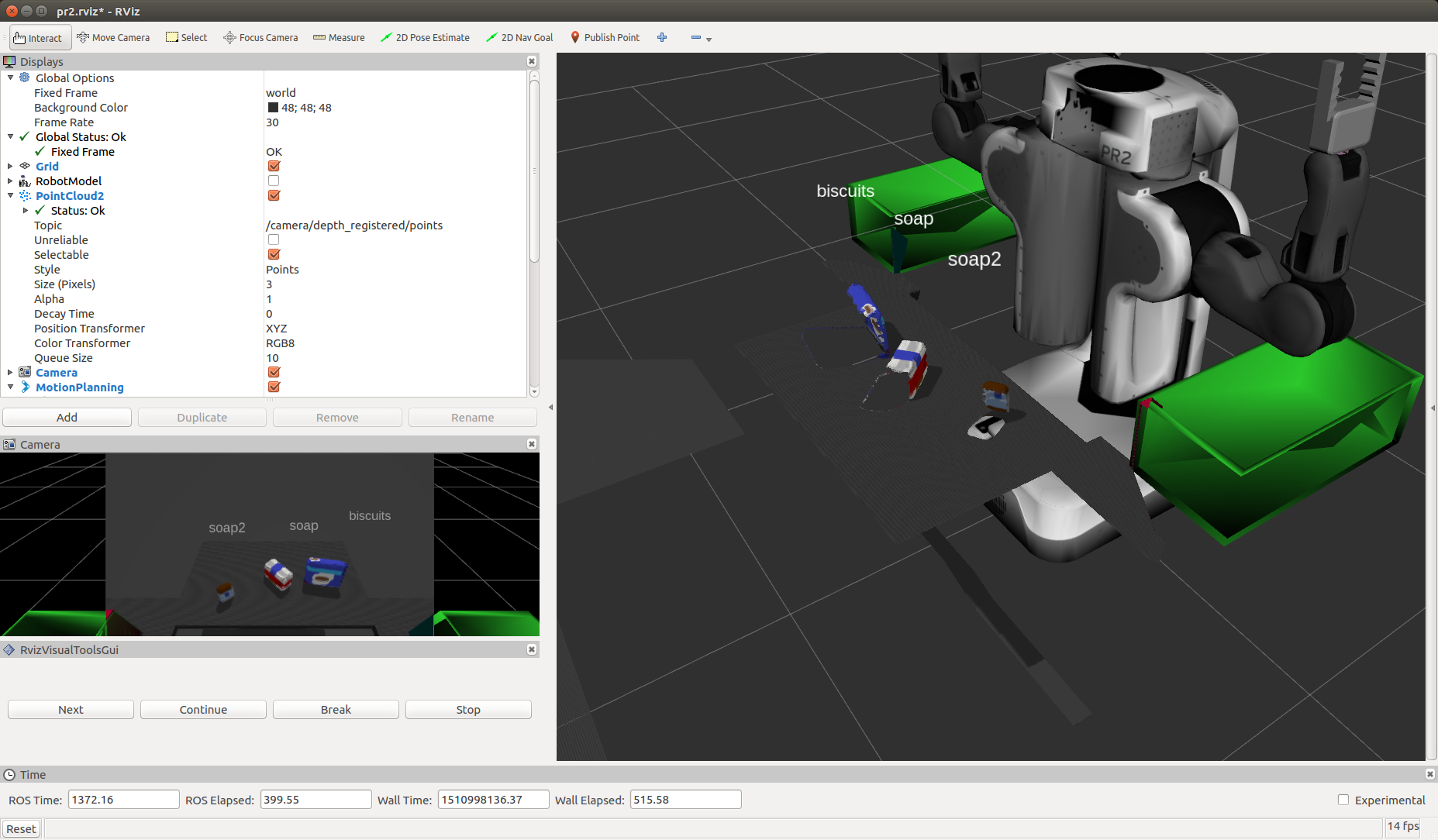
test2.world
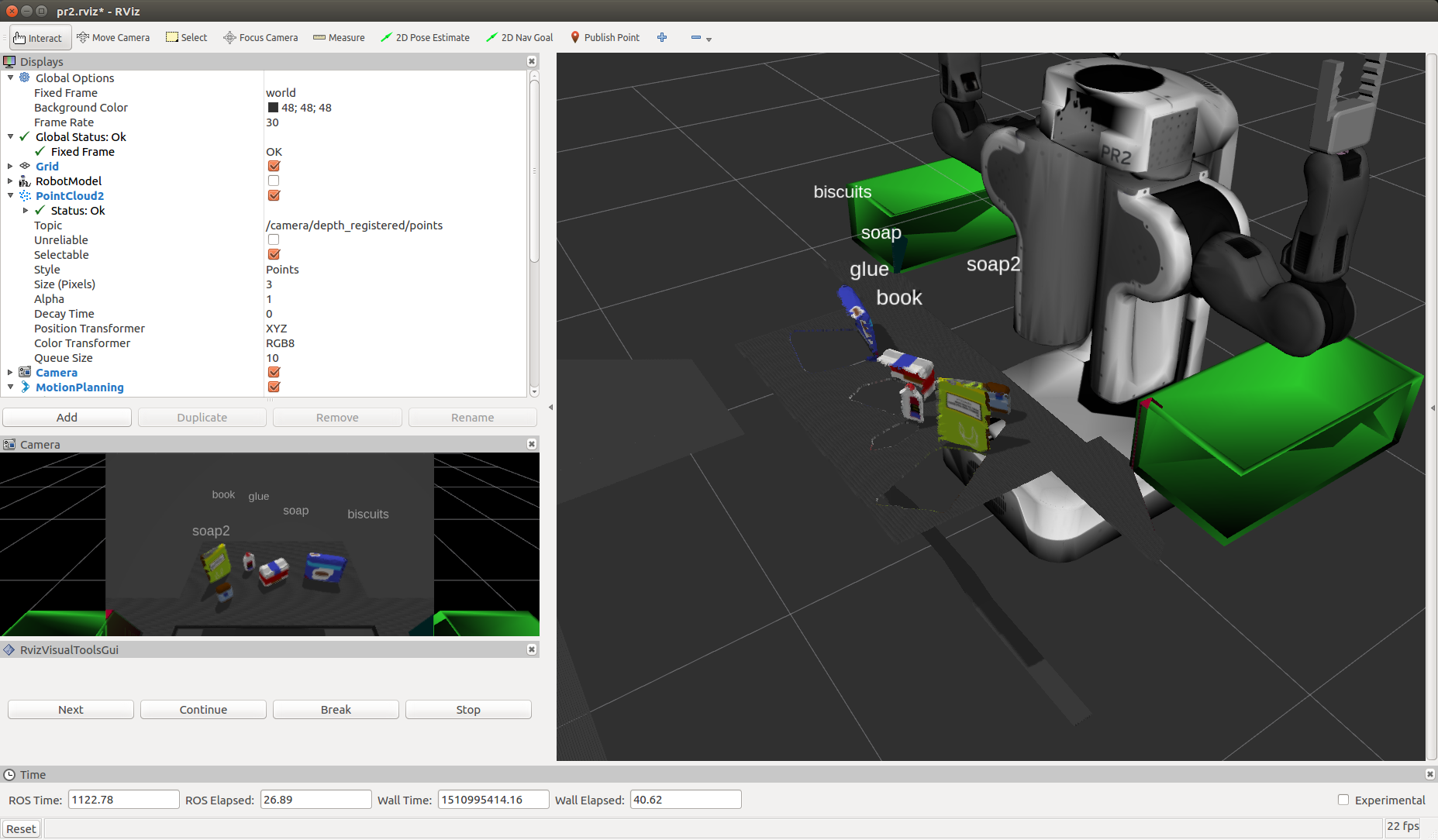
test3.world
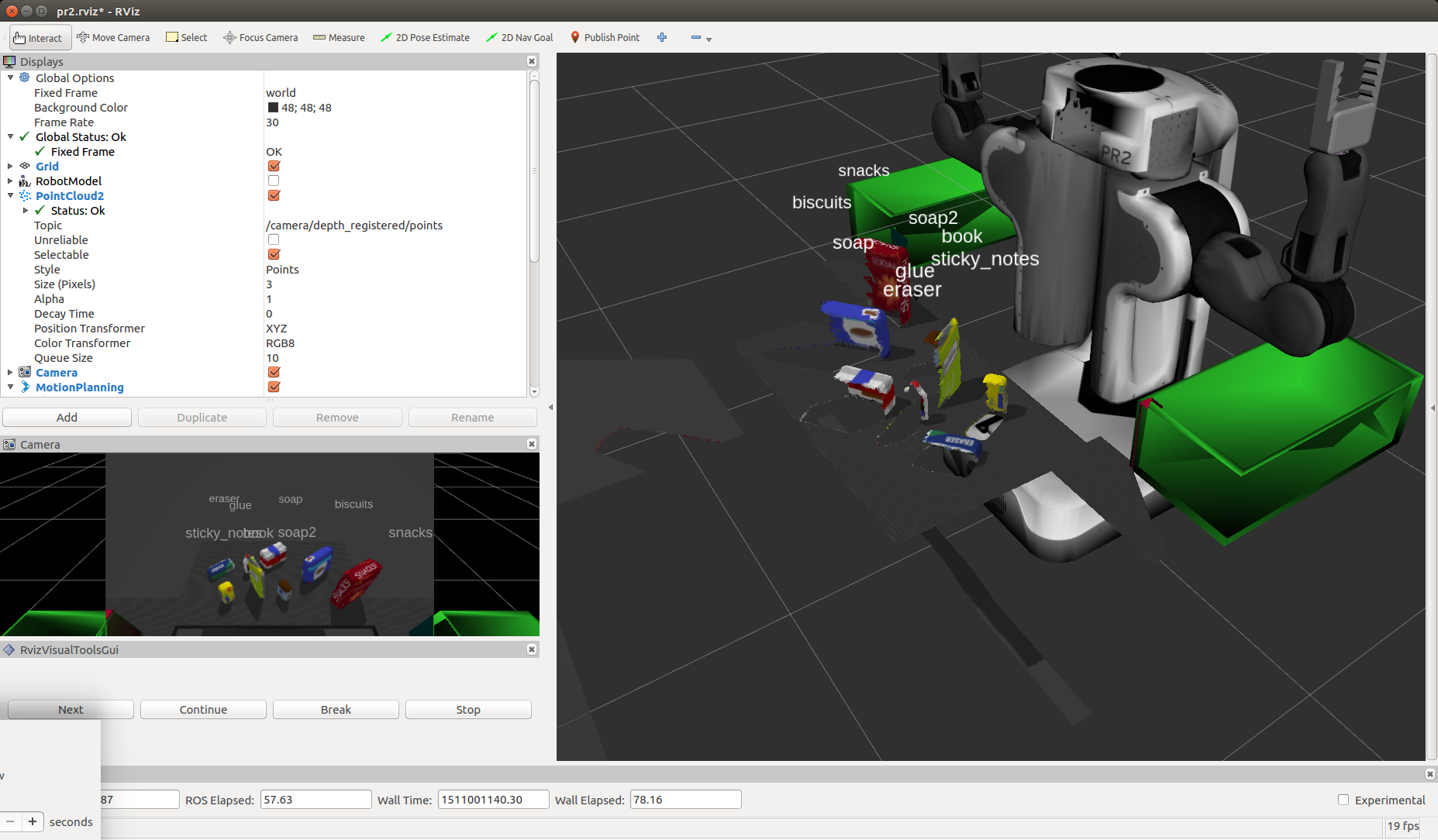
Reflection
It was interesting to learn about using point clouds and to learn this approach. I found occasionally there was some false readings. In addition few of the objects were picked and placed in the crates (the PR2 did not seem to grasp them properly). This may mean that further effort is needed to refine the centroid selection of each object.
Whilst I achieved average ~90% accuracy, across all models, on the classifier training, with more time spent, I would have liked to have achieved closer to 97%. This would also improve those false readings. I’m also not sure I fully understand the noise introduced in this project from the PR2 RGBD camera.
If I was to approach this project again, I’d be interested to see how a 4D Tensor would work via deep learning using YOLO and/or CNNs. Further research is required.